Gate Ventures研究洞察:Parallel Execution突破瓶頸,以太坊EVM的性能挑战與並行執行之路
我們同時也注意到了,雖然並行執行像是指數級拓展了區塊鏈,但是其仍然有瓶頸,這個瓶頸是分布式系統天生的,包括P2P網絡、數據庫本身吞吐量等問題。區塊鏈計算想要達到傳統計算機的計算能力,仍然有很長的路要走。目前並行執行本身也面臨一些問題,包括並行執行的硬件要求越來越高,節點越來越專業化帶來的中心化、審查風險,並且在機制設計上依賴於內存、中心集群或者節點也會帶來宕機風險,與此同時,在並行區塊鏈間跨鏈通信也會是一個問題。這仍然值得更多團隊去探索。
從各家的架構以及對 EVM 的兼容的思考中,我們深知,顛覆性創新來自於對過去的不妥協。區塊鏈技術仍然在早期,而性能提升也遠未到達終局,我們迫不及待的想要見到更多不愿意妥協、不循規蹈矩的創業者構建更加強大且有趣的產品。
Ethereum 的單线程問題
Ethereum EVM 一直以來在性能上都飽受詬病,主要是由於其落後的架構設計,其中不支持並行化的問題是最為嚴重的。對於交易並行化,相當於一條馬路變成了多道跑道,這能為道路上的可容納流量帶來指數級的提升。
深入 Ethereum,在當前執行層與共識層分離的背景下,我們會發現 EVM 的交易處理全部是串行執行。
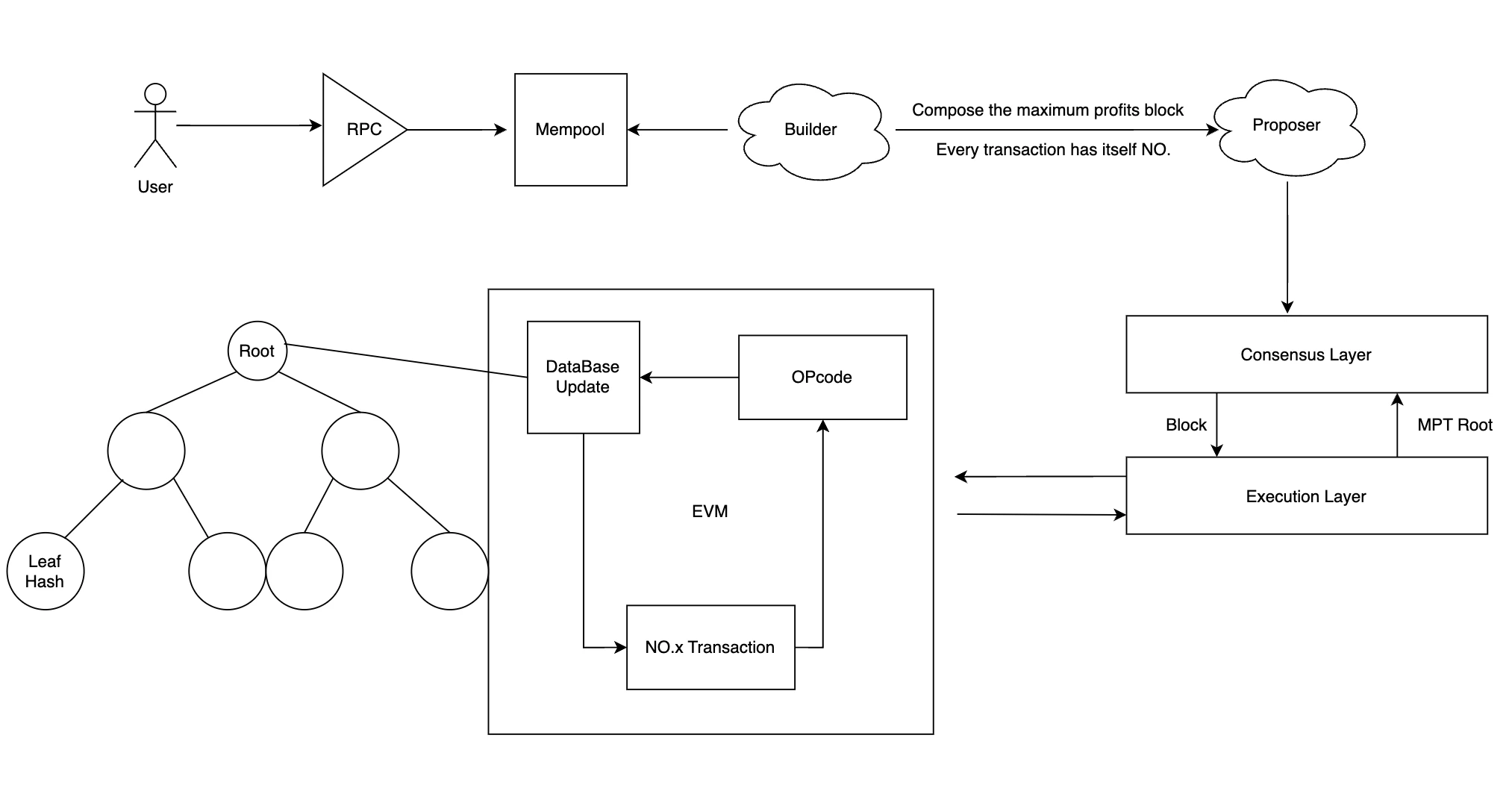
以太坊的交易執行流程
在以太坊的交易中,用戶首先會將交易通過 RPC 發送到 Mempool,之後 Builder 選擇利潤最大化的交易,並且將其排序,此時交易的順序已經確定。 Proposer 將交易廣播給共識層,共識層確定該區塊的有效性,比如是來自有效的發送着,區塊中的交易作為執行負載發送給執行層,執行層執行交易,執行交易的簡略過程如下:(以 Alice 發送 1 ETH 給 Bob 為例)
1. 在執行節點的 EVM 中,其會把 NO.0 的交易指令轉換為 EVM 能夠識別的 OPcode 代碼。
2. 然後根據 OPcode 硬編碼,確定這筆交易需要的 Gas。
3. 執行的交易過程中,需要訪問數據庫得到 Alice 和 Bob 余額的狀態,然後執行交易 opcode 知道 Alice 余額減一,Bob 加一,向數據庫寫入/更新這一余額狀態。
4. 從區塊中,取出 NO.1 的交易繼續順序的循環執行,直到該區塊的交易執行完畢。
5. 數據庫中的數據主要是以 Merkel 數的形式來存儲的,最終該區塊的交易全部順序執行完畢以後,數據庫中的狀態根(存儲账戶狀態)、交易根(存儲交易的順序)、收據根(存儲交易的附帶信息,如成功狀態和 Gas Fees)會提交到共識層。
6. 共識層收到狀態根即可非常輕便的證明交易的真實性,執行層將驗證數據傳回共識層,區塊現在被視為已驗證。
7. 共識層將區塊添加到其自己的區塊鏈的頭部並對其進行證明,並通過網絡廣播該證明。
這個就是整個全流程,裏面涉及到了區塊內交易的順序執行,主要是每一筆交易都有自己的 NO,並且每一筆交易都可能需要讀取數據庫中的狀態,並且重寫狀態。如果不是順序執行,那么就會導致狀態衝突,因為有一些交易是相互依賴狀態的。所以,這也是為什么 MEV 選擇串行執行的原因。
MEV 的簡單,這同時也意味着,帶來了串行執行帶來了極低的性能表現,這是導致以太坊僅僅兩位數 TPS 的主要原因之一。在現在的聚焦消費者應用程序的發展背景下,EVM 作為落後的設計範式,面臨着亟待改善的性能問題,雖然當前 EVM 已經走向了一個完全以 Layer 2 為中心的路线圖,但是其 EVM 的問題,如 MPT trie 結構,數據庫如 LevelDB 的低效等都是亟待解決的。
伴隨着這一問題的演進,有許多項目开始着手構建並行高性能 EVM,以此來解決以太坊老舊的設計範式。通過在 EVM 的流程中,能夠看出這裏有兩個高性能 EVM 主要解決的問題:
1. 交易狀態分離:交易由於存在狀態的相互依賴,因此需要串行運行,需要將狀態獨立的交易分離出來,然後想依賴的仍然需要順序執行。那么就可以分發給多個核心並行處理。
2. 數據庫架構改進:以太坊使用 MPT 樹,由於一筆交易涉及大量的讀取操作,通常情況下,這會導致極高的數據庫的讀寫操作,也就是 IOPS(IO Per Second)要求極高,通常的消費級 SSD 無法滿足這一需求。
總的來說,目前的主流的區塊鏈構建方案中, 往往在軟件上的優化主要是交易狀態的分離以構建可並行的交易以及數據庫的優化以支持高並發的交易狀態讀取。 伴隨着對高性能的需求,大多數項目的對硬件的需求也在提高。以太坊一直以來對於 Layer 1 的性能拓展都非常謹慎,因為這意味着中心化與不穩定性。但是當前的高性能 EVM 往往拋棄了這些給自己添加的桎梏,引入了極致的軟件改進、P2P網絡優化、數據庫重構、企業級專業硬件。
衍生的數據庫 IOPS 問題
並行執行的識別與分離其實在理解上不難,主要難和較少被公衆討論的是數據庫的 IOPS 問題。在本文中,我們也將用實際例子,讓讀者感受到區塊鏈數據庫面臨的復雜難題。
在以太坊中,全節點實際上安裝的是虛擬機,可以認為就是我們的普通計算機,我們的數據都存儲在專業的軟件中——數據庫。以這個軟件來管理龐大的數據。不同的行業數據有不同的數據庫類型的需求,比如 AI 這種數據種類龐雜的領域比較火熱的就是矢量數據庫。在區塊鏈領域如以太坊使用的就是較為簡單的 Key-Value Pair 的數據庫。
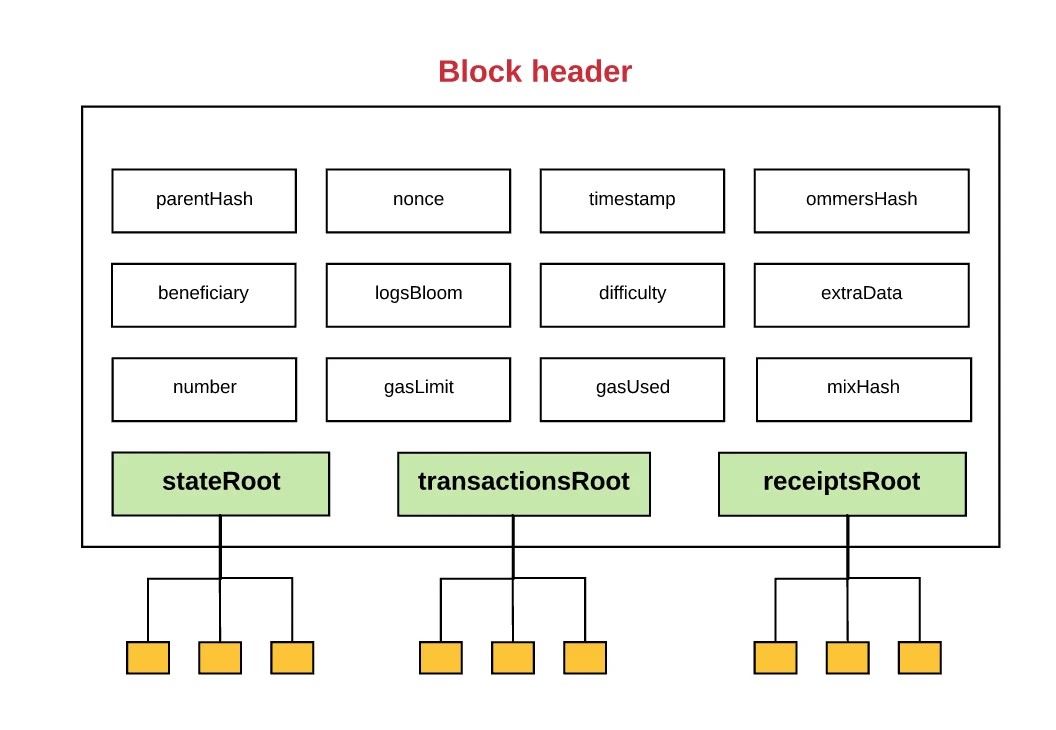
以太坊數據組織方式示意圖,圖源: Github
通常數據庫中的數據都會以一種抽象的方式組織在一起,以太坊就是以 MPT 樹的方式。MPT 樹最後的數據狀態會形成一個根節點,如果任何的數據有了更改,根節點都會變化,因此使用 MPT 能夠很便捷的驗證數據完整性。
我們舉一個例子來感受一下當前數據庫的資源消耗情況:
在一個擁有 n 個葉子節點的 k 叉 Merkle Patricia Tree(MPT)中,更新單個鍵值對需要進行 O( klog k n ) 次讀取操作和 O( log k n ) 次寫入操作。比如,對於一個擁有 160 億個鍵(即 1 TB 區塊鏈狀態)的二叉 MPT,這相當於大約 68 次讀取操作和 34 次寫入操作。假設我們的區塊鏈想要處理每秒 10, 000 筆轉账交易,需要更新狀態樹中的三個 key-value,一共需要 10 , 000 x 3 x 68 = 2 , 040 , 000 次,也就是 2 M IOPS(I/O Per Second)操作(在實踐中,可以通過壓縮和緩存減小一個數量級,大約是 20 萬 IOPS,我們不做展开)。目前主要的消費級 SSD 完全無法支持這一操作(Intel Optane DC P 580 0X 800 GB 僅僅為 10 萬 IOPS)。
MPT 樹當前面臨了許多問題,包括:
● 性能問題:MPT 由於其層次化的樹結構,在更新數據時,往往需要遍歷多個節點。每次狀態更新(如轉账或智能合約執行)需要進行大量的哈希計算,並且由於需要訪問許多層的節點,性能較低。
● 狀態膨脹:隨着時間推移,區塊鏈上的智能合約、账戶余額等狀態數據會不斷增加,導致 MPT 樹的大小持續膨脹。這會導致節點需要存儲越來越多的數據,給存儲空間和同步節點帶來了挑战。
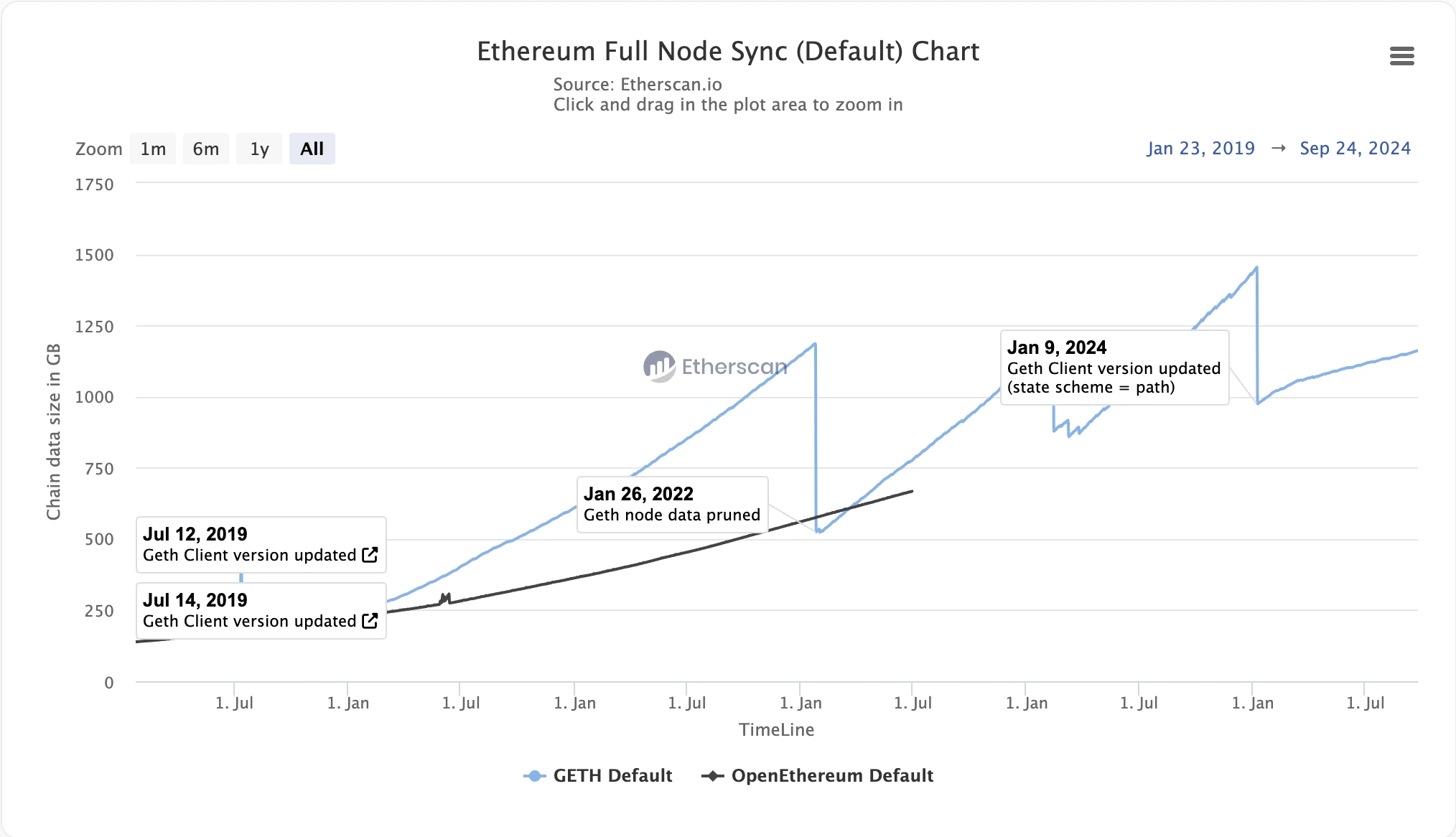
以太坊狀態膨脹情況(涉及到狀態修剪),圖源: Etherscan
● 無法高效處理部分更新:當樹結構中的某個葉子節點發生變化時,整個路徑上的節點都會受到影響。以太坊 MPT 需要重新計算從葉節點到根節點的所有哈希值,這導致即便是局部的狀態變更,也需要對大量的節點進行更新,從而影響性能。
我們能夠看到,當前 MPT 下的以太坊面臨多種問題,其也提出了多種解決方案,比如針對狀態膨脹會進行狀態修剪、針對 MPT 性能問題會構建新的 Verkel Tree。通過構建新的 Verkel Tree 結構的數據庫,通過減小樹的深度來減少部分更新時數據庫的訪問次數,使用向量承諾(主要以 KZG 承諾為主)來減小證明的體積同時也減少數據庫的訪問量。
總之,過去的 MPT 樹的涉及以及過於老舊,面臨了許多新的挑战,因此改變數據的存儲方式如使用 Verkel tree 已經被列入其路线圖。 但是這僅僅是非常微弱的修改,仍然並沒有涉及到並行執行以及高並發下要求的高 IOPS 的解決方案。
新公鏈標配並行執行
就如我們上一部分所言,並行執行意味着從單車道改為多車道,在多車道的十字路口往往需要一個中間件如紅綠燈協調,發送信息以使各個車道能夠順暢通過。區塊鏈也是,在並行交易中,我們需要把用戶的交易通過一個狀態識別的中間件,讓狀態互不相幹的交易能夠分離從而達到並行執行,並行執行帶來的高 TPS,同時意味着對底層數據庫的大量 IOPS 需求。幾乎所有的新 Layer 1 有以並行執行作為標配 feature。
對並行執行的實現方案有多種分類方式,按照底層的虛擬機,分為 EVM(Sei、MegaETH、Monad)和 None-EVM(Solana、Aptos、Sui)。按照交易狀態的分離方式,可以分為樂觀執行(假設全部交易都不想幹,如果狀態衝突則回退這部分交易重新執行)和提前聲明(开發者需要在程序中聲明訪問的狀態數據)。這些分類也同時意味着權衡。
接下來,我們將不以是否為 EVM 作為劃分,而是單純的從各個公鏈在狀態分離以及數據庫方面的改善情況來進行比較。
MegaETH
MegaETH 嚴格來說是一個以性能為主要目標的異構區塊鏈,其依賴於以太坊的安全性使用 EigenDA 作為共識層和 DA 層。而其作為執行層,將最大程度的釋放硬件性能提升 TPS。
對於交易處理的優化手段其分為三種:
1. 狀態分離:採用交易優先級的方式的流式區塊構建。這一模式和 Solana 的 POS 有相似之處,實際上 Solana 的交易也是流式構建的,但是 Solana 沒有優先級,全部靠速度來競爭。而 MegaETH 希望能夠為交易構建某種優先級算法。
2. 數據庫:針對 MPT Trie 的問題,其構建了新的數據結構來提供更高的 IOPS。我們查閱 MegaETH 的代碼庫時,發現其也有在同時參考 Verkel Trie 的設計方式。
3. 硬件專業化:通過將排序器中心化和專業化,實現內存計算從而顯著提高 IO 的效率。
實際上,MegaETH 希望作為 Layer 2 將安全性和抗審查性委托給 Ethereum,這樣就能夠最大限度的優化節點,通過 POS 的經濟安全性來保障排序器的不作惡,這裏有許多值得 chanllenge 的點,但是我們不做展开。雖然 MegaETH 在構建並行執行的交易,但是實際上,其目前並未實現並行執行, 其希望將單一排序器節點的性能做到極限以此最大程度的以硬件拓展性能,然後再通過並行執行拓展性能。
Monad
與 MegaETH 不同,Monad 是一條單獨的鏈,其符合我們介紹的並行執行需要優化的兩個重要的點,並行執行的狀態分離以及數據庫重構。我們簡述 Monad 使用的具體方法:
● 樂觀並行執行:對於交易的識別,採用了最為經典的默認所有交易的狀態都是不想關的,當遇到狀態衝突時,再重新運行交易,這一方式目前在 Aptos 的 Block-STM 機制上運行良好。
● 數據庫重構:Monad 為了提高數據庫的 IOPS,因此重構了兼容 EVM 的數據結構 MPT(Merkel Patricia Tree),Monad 實現了兼容 Patricia Tree 的數據結構,並且支持最新的數據庫的異步 I/O,能夠支持在讀取某個狀態時,不需要等待對該數據的寫結束。
● 異步執行:在以太坊上,雖然我們嚴格的識別了具體的共識層以及執行層,但是我們發現共識層與執行層(與 Layer 2 作為執行層的概念不相同,在這裏指以太坊仍然需要執行節點以執行以太坊上的交易)仍然是耦合在一起的,執行將執行後更新的 Merkel Root 給到共識,這樣共識層才能投票以達成共識。Monad 認為狀態在排序完成的那一刻就已經定下來了,所以只需要對排序後的交易達成共識,甚至不需要執行來揭示這一結果。這一想法,讓 Monad 能夠巧妙的將共識層與執行層拆離开來,以此來實現共識同時執行。節點可以在保持對 N 區塊的共識投票的同時,去執行 N-1 區塊的交易。
當然,Monad 還有許多其它的技術包括新的共識算法 MonadBFT 等共同構建了一個高性能的並行 EVM Layer 1 。
Aptos
Aptos 從 Facebook 的 Diem 團隊拆分而來,其與 Sui 共同視為 Move 雙雄,雖然如此,兩家因為技術理念的不一致,導致了當前兩家的 Move 語言已經大不相同,整體來說,Aptos 更遵循當初 Diem 的設計,而 Sui 對該設計進行了大刀闊斧的修改。
針對並行執行需要解決的問題:
● 狀態識別:樂觀並行執行,Aptos 开發了 Block-STM 並行執行引擎,默認樂觀執行交易,如果遇到狀態衝突,則重新執行。目前這一技術已經被普遍接受,如 Polygon、Monad、Sei、StarkNet 均使用這一技術。
● IO 改進:Block-STM 使用了多版本的數據結構以避免狀態衝突。舉個例子,假設我們其他人正在寫一個數據庫,那么正常來說,我們是無法訪問的,因為需要避免數據的衝突,但是多版本的數據結構可以允許我們訪問過去的版本。問題在於,這個方案會造成巨大的資源消耗,因為你需要為每個线程生成一個可見的版本。
● 異步執行:和 Monad 類似,交易傳播、交易排序、交易執行、狀態存儲和區塊驗證都是同時進行的。
當前 Block-STM 已經被大多數公鏈接受,並且被 Monad 稱為多虧了這一技術的出現,能夠有效減緩开發者的壓力,但是 Aptos 面臨的問題是,Block-STM 的智能化帶來了對節點要求過高的問題,這一問題需要專業化硬件以及中心化的去解決。
Sui
Sui 也和 Aptos 一樣,繼承自 Diem 項目。相比之下,Sui 使用悲觀並行化,嚴格驗證交易之間的狀態依賴關系,並採用鎖定機制來防止執行期間發生衝突。而 Aptos 希望能夠減輕开發者的开發負擔。
● 狀態識別:與 Aptosb 不同,採用了悲觀並行化,因此开發者需要聲明自己的狀態訪問,而不是將並行的狀態識別交給系統來處理,增加了开發者的开發負擔,減輕了系統的設計復雜度,同時也增加了並行化的能力。
● IO 改進:IO 改進目前主要是改進模型,以太坊使用基於账戶的模型,每個账戶維護其數據,但是 Sui 採用了 Objects 的結構代替账戶模型,該架構的改進會顯著影響並行性實施的難度與峯值性能。
Sui 因為不存在 EVM 的歷史遺留問,也沒有兼容性的問題,其基於 Move 系都進行大刀闊斧的更改,對於账戶模型,其也提出了創新性的想法 Objects,這種抽象層面上的創新實際上更難。但是其 Objects 模型帶來了對並行處理的諸多好處,也是因為 Objects 模型,其構建了一個非常與衆不同的網絡架構,在理論上確實能夠無限拓展。
Solana - FireDancer
Solana 被視為並行計算的先驅,Solana 的理念一直以來都是區塊鏈系統應該隨着硬件的進步而進步,以下是當前 Solana 的並行處理方式:
● 狀態識別:與 SUI 一樣,Solana 也使用確定性並行方式,這來自於 Anatoly 過去處理嵌入式系統的經驗,在嵌入式系統中,通常會預先聲明所有狀態。這使 CPU 能夠知道所有的依賴關系,從而使它能夠預先載入內存的必要部分。結果就是優化了系統執行,但是再一次,它要求开發人員預先做好額外的工作。在 Solana 上,程序的所有內存依賴都是必需的,並在構建的交易(即訪問列表)中進行聲明,從而使運行時(runtime)能夠高效地調度及並行執行多個交易。
● 數據庫:Solana 利用 Cloudbreak 構建了自己的自定義帳戶數據庫,其使用的是以账戶為模型,帳戶數據分布在多個“分片”上,類似於將圖書館分為幾層,並且其可以根據需要增加或者減少層數以負載均衡。其在 SSD 上會映射給內存,因此通過流水线設計可以快速通過內存操作 SSD,同時支持多數據的並行訪問,能夠同時並行處理 32 個 IO 操作。
Solana 通過確定性並行方式要求开發者聲明其需要訪問的狀態,這確實與傳統的變成情況相似,在程序構建方面是需要开發者自己構建並行應用程序,而程序調度和運行時流水线異步並行則是項目需要構建的。在數據庫方面,其通過自建自己的 DataBase 進行數據並行化以提高 IPOS。
於此同時,後續的 Solana 迭代的客戶端,Firedancer 是由 Jump Trading 這一具有非常強大工程能力的量化巨頭所推動研發的,與 Solana 的愿景相同,目標是消除軟件效率低下並將性能推向硬件的極限。其改進主要是針對硬件底層的改進,包括P2P傳播、硬件的 SIMD 數據並行處理等,這與 MegaETH 的想法非常相似。
Sei
Sei 目前使用的是
● 樂觀並行執行:參考自 Aptos 的 Block-STM 設計。Sei V1版本使用的是類似於 Sui、Solana 的消極並行方案也就是需要开發者自己聲明使用的對象,但是在 Sei V2後,其改成了 Aptos 的樂觀並行方案。這會對可能缺乏开發者的 Sei 有所助益,能夠更加便捷的將合約從 EVM 生態遷移過來。
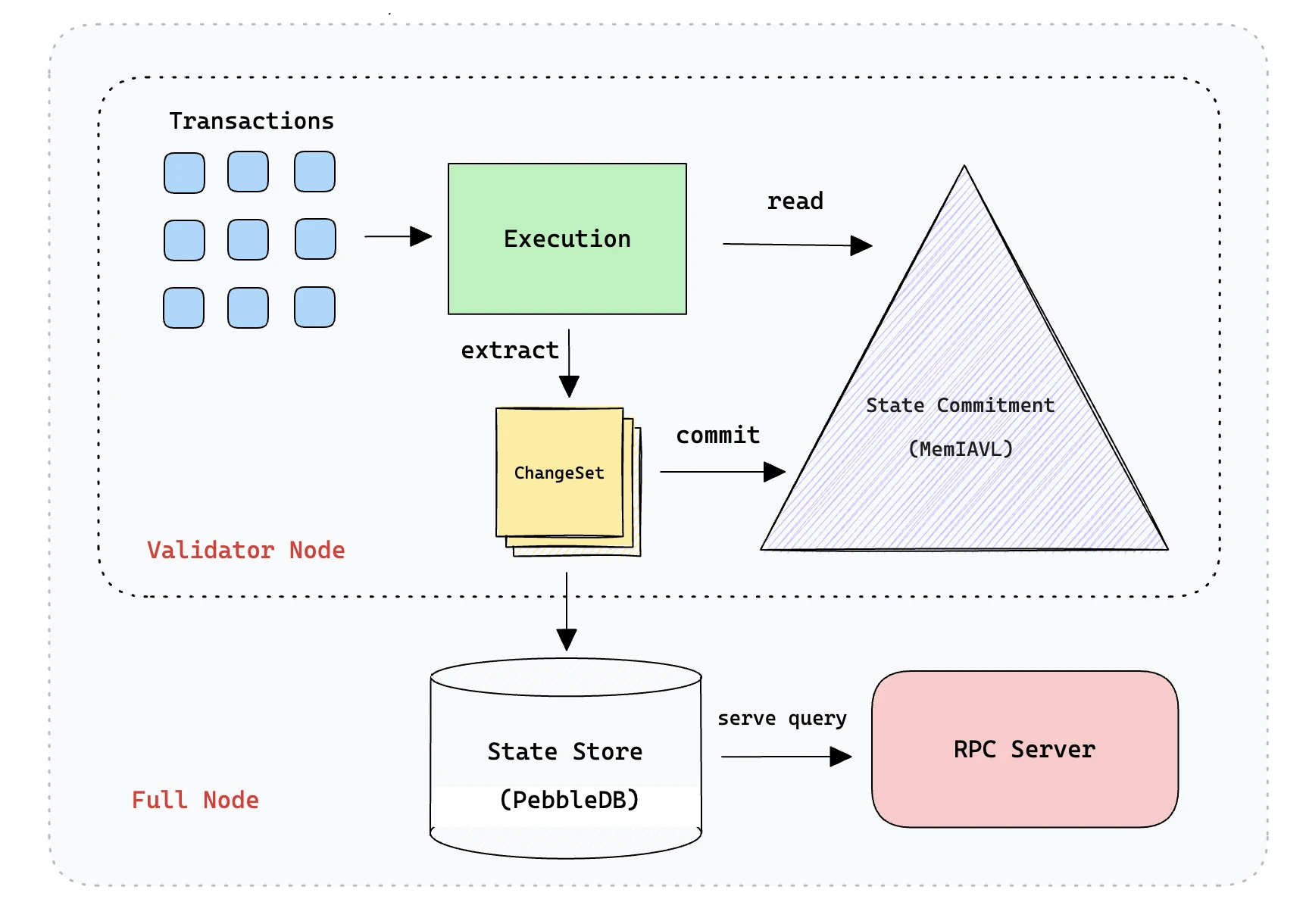
SeiDB 設計,圖源: Sei
● SeiDB:整個數據庫解決方案是基於 Cosmos 的 ADR-065 提案基礎上構建的,其實體使用的是 PebbleDB ,數據結構的設計上將數據分為活動數據和歷史數據,SSD 硬盤內的數據映射成內存上的數據,同時 SSD 數據使用 MemIAVL 樹結構,而內存數據使用 IAVL 樹( Cronos 發明)進行狀態承諾,就是其提供運行共識的狀態根。MemIAVL 的抽象思想是,每次提交新塊時,我們都將從該塊的交易中提取所有更改集,然後將這些更改應用於當前內存中的 IAVL 樹,從而為最新塊生成樹的新版本,以便我們可以獲得塊提交的 Merkle 根哈希。因此,相當於使用內存進行熱更新,這能讓大部分的狀態訪問都位於內存上,而不是 SSD,以此來提升 IOPS。
SeiDB 的主要問題是,如果最新的活躍數據存放在內存上,那么會出現宕機數據丟失的情況,所以 MemIAVL 引入了 WAL 文件和樹快照。在一定的時間內,需要快照內存上的數據,存放在本地的硬盤上,控制一定的時間快照間隔,及時控制數據膨脹對內存的 OOM 影響。
並行對比
Full-node Requirement
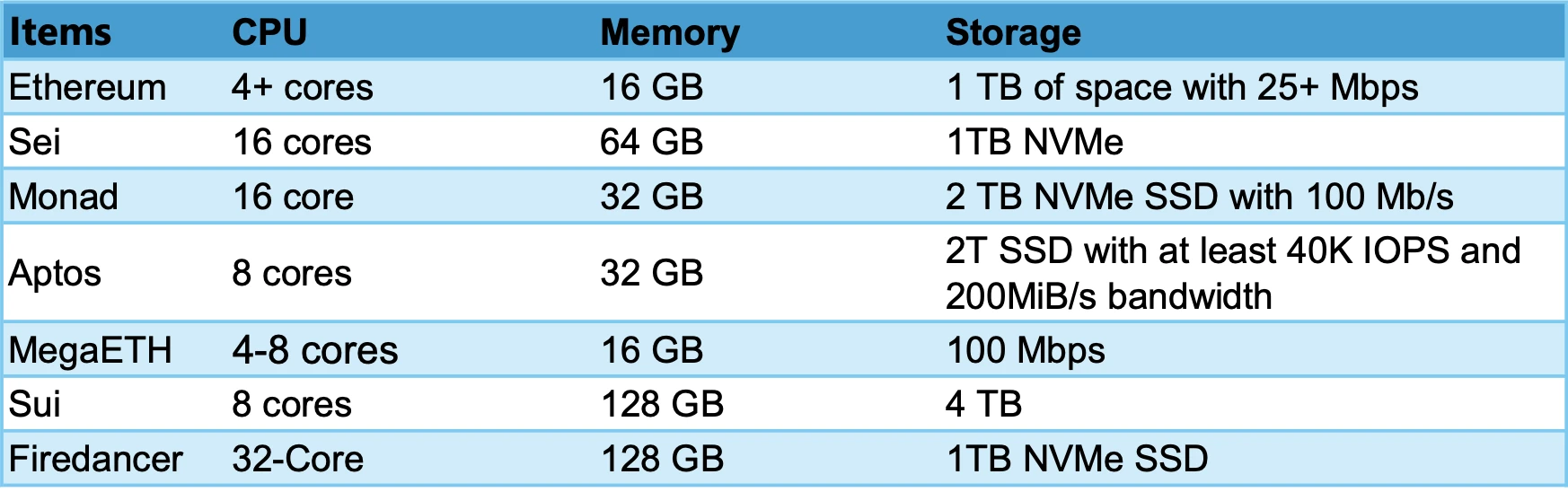
運行全節點要求
FireDancer 對節點的運行要求是最高的,可以稱為是性能怪獸。MegaETH 的主要性能要求集中在 Sequencer 要求具備 100+cores。而由於存在中心化的節點 sequencer,所以其它 full node 節點要求並不高。目前 SSD 價格均較低,所以一般我們看 CPU 和 Memory 的性能要求即可。我們將 Full Node 性能要求從高到底排序分別是:Firedancer > Sei > Monad > Sui > Aptos > MegaETH > Ethereum.
方案
目前的並行處理的方案,一般來說,我們在軟件層面的優化主要是 1. 數據庫 IOPS 消耗問題 2. 狀態識別問題 3. 流水线異步問題 ,這三方面進行軟件層面的優化。狀態識別目前分為兩個陣營,分別是樂觀並行執行和聲明式編程。這兩種都有利有弊,其中樂觀並行執行主要是以 Aptos 的 Block-STM 方案為主,其主要 c 採用者包括 Monad、Sei V2,而 Sui、Solana、Sei V1都是聲明式編程,這個比較類似於傳統的並發或者異步編程的範式。對於數據庫的 IPOS 消耗問題,各家的解決方案就較為不同:
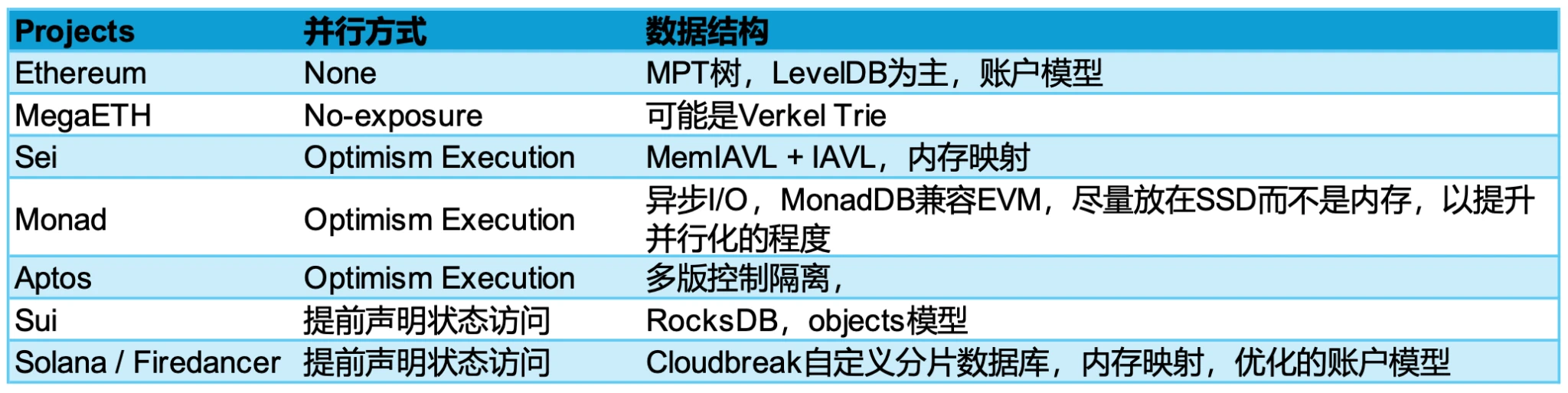
方案對比
對於數據結構,我們看到一個比較有趣的一點,Monad 盡量放在 SSD,但是硬盤的讀取速度遠低於 Memory 內存,但是價格便宜很多。Monad 放在 SSD 考慮了價格、硬件門檻以及並行程度,因為現在 SSD 能夠支持 32 通路的 I/O 操作,以此提升更多的並行能力。相反,Solana、Sei 卻選擇內存映射,因為內存的速度遠高於 SSD。一個是橫向拓展並行通路,一個是縱向拓展降低 I/O 消耗。這也是出現了 Monad 的節點要求是 32 GB,但是 Sei 和 Solana 需要更多內存的原因。
除此之外,以太坊的數據結構是由 Patrci Tree 演進得到 Merkel Patric Tree 得來,所以 EVM 兼容的公鏈需要兼容 Merkel Trie,因此其無法構建像 Aptos、Sui、Solana 等抽象方式去思考資產,以太坊是以账戶模型,但是 Sui 是 Objects 模型、Solana 是數據與代碼分離的账戶模型,而以太坊確實耦合在一起的。
顛覆性創新來自於對過去的不妥協,在商業的角度確實也需要考慮开發者群體以及過去的兼容性,對 EVM 的兼容有其利弊。
展望
當前並行執行的主要優化組件都有了比較清晰的目標,主要集中在如何識別狀態、如何提高數據的讀取和存儲的速度,因為這些數據的存儲方式會導致讀取或者存儲一個數據造成額外的开銷與消耗,特別是 Merkel trie 引入了根驗證這一有點,但是帶來了超級高額的 IO 开銷。
雖然並行執行,像是指數級拓展了區塊鏈,但是其仍然有瓶頸,這個瓶頸是分布式系統天生的,包括P2P網絡、數據庫、等問題。區塊鏈計算想要達到傳統計算機的計算能力,仍然有很長的路要走。目前並行執行本身也面臨一些問題,包括並行執行的硬件要求越來越高,節點越來越專業化帶來的中心化、審查風險,並且在機制設計上依賴於內存、中心集群或者節點也會帶來宕機風險,與此同時,在並行區塊鏈間跨鏈通信也會是一個問題。
雖然,目前並行執行仍然有一定問題,各家都在探索最佳的工程實踐,包括以 MegaETH 為首的模塊化設計架構和 Monad 為首的單片鏈設計架構。目前並行執行的優化方案,確實證明了區塊鏈技術正在不斷的朝着傳統的計算機優化方案靠近,並且越來越底層進行優化,特別是數據存儲、硬件、流水线等技術上的細致優化。但是,這句仍然存在瓶頸和問題,因此仍然有非常廣闊的探索空間留給創業者。
顛覆性創新來自於對過去的不妥協,我們迫不及待的想要見到更多不愿意妥協的創業者構建更加強大且有趣的產品。
免責聲明:
以上內容僅供參考,不應被視為任何建議。在進行投資前,請務必尋求專業建議。
關於 Gate Ventures
Gate Ventures 是 Gate.io 旗下的風險投資部門,專注於對去中心化基礎設施、生態系統和應用程序的投資,這些技術將在 Web 3.0 時代重塑世界。 Gate Ventures 與全球行業領袖合作,賦能那些擁有創新思維和能力的團隊和初創公司,重新定義社會和金融的交互模式。
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
為何散戶寧可在鏈上參與高風險的 PVP 陰謀幣博弈,也對 VC 背書的新幣敬而遠之?
撰文:haotian 來源:haotian 這兩天二級市場一些新幣集體回落,似乎反映了市場對當前周...
Odaily專訪OKX全球首席商務官Lennix:自托管仍是Web3錢包的未來
@OdailyChina @web3_golem Odaily: 這次參加 Web3 嘉年華大會,...
星球日報
文章數量
8954粉絲數
0
評論