模塊化被忽視的領域:執行、結算與聚合層
就關注度和創新性而言,模塊化堆棧的各個組成部分並非都一樣。雖然此前有許多項目在數據可用性 (DA) 和排序層上進行了創新,但直到最近,執行層和結算層才作為模塊化堆棧的一部分被重視起來。
共享排序器領域競爭激勵,Espresso、Astria、Radius、Rome 和 Madara 等許多項目在爭奪市場份額 ,此外還有包括像 Caldera 和 Conduit 這樣的 RaaS 提供商,它們為在其基礎上構建的 Rollup 开發共享排序器。這些 RaaS 提供商能夠為 Rollup 提供更優惠的費用,因為它們的底層商業模式並不完全依賴於排序收入。還有許多 Rollup 選擇運行自己的排序器以獲取它產生的費用。
與 DA 領域相比,排序器市場是獨一無二的。DA 領域基本上由 Celestia、Avail 和 EigenDA 組成的寡頭壟斷。這使得除了三大巨頭之外的較小新進入者很難成功顛覆該領域。項目要么利用「現有」選擇(以太坊);要么根據自身的技術堆棧類型和一致性選擇其中一個成熟的 DA 層。雖然使用 DA 層可以節省大量成本,但外包排序器部分並不是一個明顯的選擇(從費用角度來看,而不是安全性),主要是因為放棄排序器收入的機會成本。許多人還認為 DA 將成為一種商品,但我們在加密貨幣中看到,超強的流動性護城河與獨特(難以復制)的底層技術相結合,使得將堆棧中的某一層商品化變得極其困難。無論這些爭論如何,都有許多 DA 和排序器產品推出。簡而言之,對於一些模塊化堆棧,「每項服務都有幾個競爭對手。」
我認為,執行和結算(以及聚合)層相對而言尚未得到充分探索,但它們正开始以新的方式進行迭代,以便與模塊化堆棧的其余部分更好地保持一致。
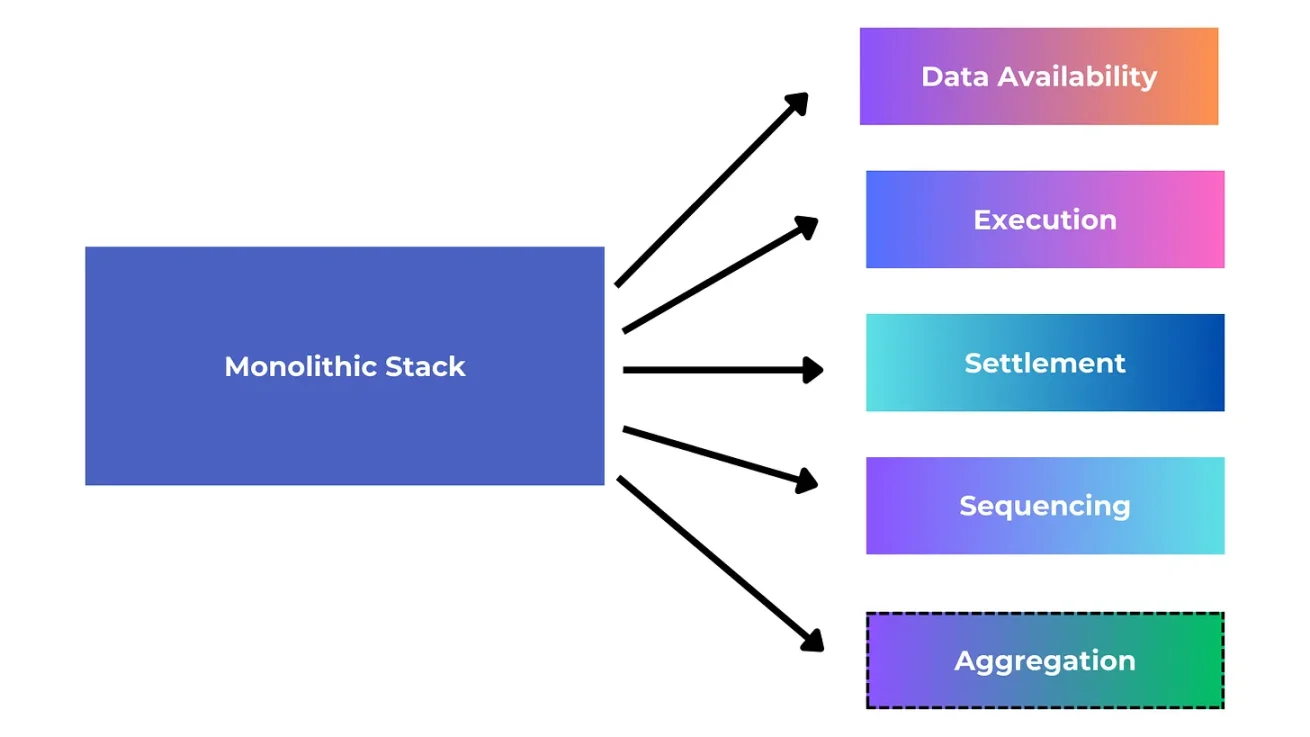
執行與結算層關系
執行層和結算層緊密集成,其中結算層可以作為定義狀態執行最終結果的地方。結算層還可以為執行層的結果添加增強功能,使執行層更加強大和安全。這在實踐中可能意味着許多不同的功,例如結算層可以作為執行層解決欺詐糾紛、驗證證明和連接其他執行層的環境。
值得一提的是,有些團隊在自己的協議中直接支持开發自定執行環境,例如 Repyh Labs ,它正在構建一個名為 Delta 的 L1。這本質上是模塊化堆棧的對立設計,但仍然在一個統一的環境中提供了靈活性,並且具有技術兼容性優勢,因為團隊不必花時間手動集成模塊化堆棧的每個部分。當然,缺點是從流動性角度來看是孤立的,無法選擇最適合你的設計的模塊化層,而且成本太高。
其他團隊則選擇針對某一核心功能或應用構建 L1。Hyperliquid 就是一個例子,它為其旗艦原生應用(永續合約交易平臺)構建了一個專用 L1。雖然他們的用戶需要從 Arbitrum 進行跨鏈,但他們的核心架構並不依賴於 Cosmos SDK 或其他框架,因此可以針對其主要用例進行迭代定制和優化。
執行層進展
上個周期中通用型 alt-L1 唯一勝過以太坊的功能是更高的吞吐量。這意味着,如果項目想要大幅提高性能,基本上必須選擇從頭开始構建自己的 L1,主要是因為以太坊本身還沒有這項技術。從歷史上看,這只是意味着將效率機制直接嵌入到通用協議中。在這個周期,這些性能改進是通過模塊化設計實現的,而且是在最主要的智能合約平臺以太坊上。這樣一來,現有項目和新項目都可以利用新的執行層基礎設施,同時又不會犧牲以太坊的流動性、安全性和社區護城河。
目前,我們還看到作為共享網絡的一部分,不同 VM(執行環境)的混合和匹配越來越多,這為开發人員提供了靈活性以及在執行層上更好的定制性。例如,Layer N 允許开發人員在其共享狀態機之上運行通用 Rollup 節點(例如 SolanaVM、MoveVM 等作為執行環境)和特定於應用程序的 Rollup 節點(例如 永續 DEX、訂單薄 DEX)。他們還致力於實現這些不同 VM 架構之間的完全可組合性和共享流動性,這是一個歷史上難以大規模完成的鏈上工程問題。Layer N 上的每個應用程序都可以在共識方面無延遲地異步傳遞消息,這通常是加密貨幣的「通信开銷」問題。每個 xVM 還可以使用不同的數據庫架構,無論是 RocksDB、LevelDB 還是從頭开始創建的自定義同步 / 異步數據庫。互操作性部分通過「快照系統」(一種類似於 Chandy-Lamport 算法的算法)工作,其中鏈可以異步轉換到新區塊而無需系統暫停。在安全方面,如果狀態轉換不正確,可以提交欺詐證明。通過這種設計,他們的目標是最大限度地縮短執行時間,同時最大限度地提高整體網絡吞吐量。
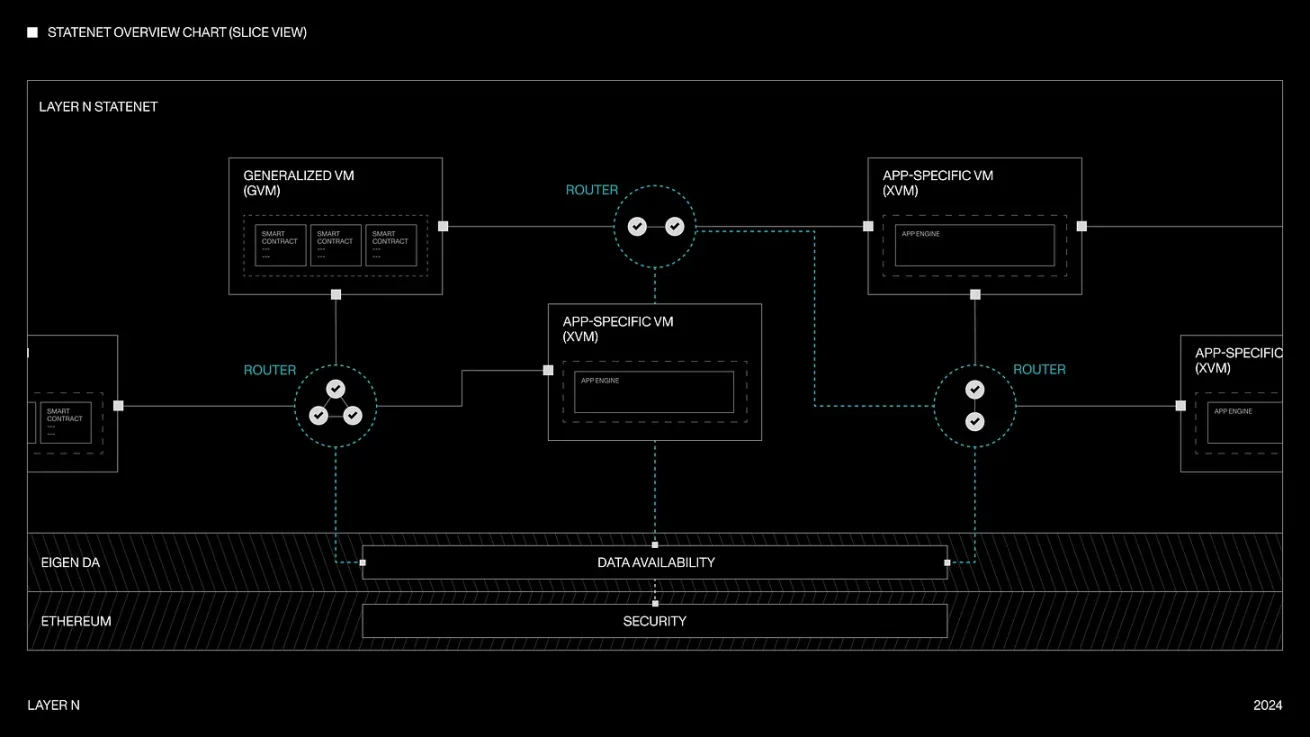
Layer N
為了推動定制化的進步,Movement Labs 利用 Move 語言(最初由 Facebook 設計並用於 Aptos 和 Sui 等網絡)進行 VM/ 執行。與其他框架相比,Move 具有結構性優勢,主要是安全性和开發人員靈活性。從歷史上看,這是使用現有技術構建鏈上應用的兩個主要問題。重要的是,开發人員也可以只編寫 Solidity 並在 Movement 上部署。為了實現這一點,Movement 創建了一個完全兼容字節碼的 EVM 運行時,該運行時也可以與 Move 堆棧一起使用。他們的 Rollup M 2 利用 BlockSTM 並行化,這允許更高的吞吐量,同時仍然能夠訪問以太坊的流動性護城河(歷史上,BlockSTM 僅用於 Aptos 等 alt L1,而 Aptos 顯然缺乏 EVM 兼容性)。
MegaETH 也在推動執行層領域的進步,特別是通過其並行化引擎和內存數據庫,其中排序器可以將整個狀態存儲在內存中。在架構方面,他們利用:
-
本機代碼編譯使 L2 的性能更加出色(如果合約的計算密集程度更高,則程序可以獲得大幅加速,如果計算密集程度不是很高,則仍然可以獲得約 2 倍以上的加速)。
-
相對中心化的區塊生產,但去中心化的區塊驗證和確認。
-
高效的狀態同步,其中完整節點不需要重新執行交易,但它們需要了解狀態增量,以便可以應用於其本地數據庫。
-
Merkle 樹更新結構(通常更新樹會佔用大量存儲空間),而他們的方法是一種內存和磁盤效率高的新 trie 數據結構。內存計算允許他們將鏈狀態壓縮到內存中,因此執行交易時,它們不必進入磁盤,只需進入內存即可。
作為模塊化堆棧的一部分,最近探索和迭代的另一個設計是證明聚合:定義為一個證明器,它創建多個簡潔證明的單一簡潔證明。首先,讓我們整體地研究一下聚合層及其在加密領域的歷史和當前趨勢。
聚合層的價值
從歷史上看,在非加密貨幣市場中,聚合器的市場份額小於平臺:

雖然我不確定這是否適用於加密貨幣的所有情況,但對於去中心化交易所、跨鏈橋和借貸協議來說,這個結論依然適用。
例如,1inch 和 0x(兩家主要的 DEX 聚合器)的總市值約為 10 億美元,僅為 Uniswap 約 76 億美元市值的一小部分。跨鏈橋也是如此:與 Across 等平臺相比,Li.Fi 和 Socket/Bungee 等跨鏈橋聚合器的市場份額更小。雖然 Socket 支持 15 種不同的跨鏈橋,但它們的總跨鏈交易量實際上與 Across 相似(Socket — 22 億美元,Across — 17 億美元),而 Across 僅佔 Socket/Bungee 最近交易量的一小部分。
在借貸領域,Yearn Finance 是首個去中心化借貸收益聚合協議,其市值目前約為 2.5 億美元。相比之下,Aave(約 14 億美元)和 Compound(約 5.6 億美元)等平臺的估值更高。
傳統金融市場情況類似。例如,ICE (洲際交易所)US 和芝加哥商業交易所集團各自的市值約為 750 億美元,而像嘉信理財和 Robinhood 這樣的「聚合器」分別擁有約 1, 320 億美元和約 150 億美元的市值。在通過 ICE 和 CME 等衆多場所進行路由的嘉信理財中,通過它們路由的交易量比例與其市值份額不成比例。Robinhood 每月大約有 1.19 億份期權合約,而 ICE 約為 3, 500 萬份——而且期權合約甚至不是 Robinhood 商業模式的核心部分。盡管如此,ICE 在公开市場上的估值比 Robinhood 高出約 5 倍。因此,作為應用程序級聚合接口,嘉信理財和 Robinhood 將客戶訂單流路由到各個場所,盡管它們的交易量很大,但估值並不像 ICE 和 CME 那么高。
作為消費者,我們給予聚合器的價值較低。
如果聚合層嵌入到產品 / 平臺 / 鏈中,這在加密貨幣中可能不成立。如果聚合器直接緊密集成到鏈中,顯然這是一種不同的架構,我很想知道它會如何發展。一個例子是 Polygon 的 AggLayer ,开發人員可以輕松地將他們的 L1 和 L2 連接到一個網絡中,該網絡可以聚合證明並在使用 CDK 的鏈之間實現統一的流動性層。

AggLayer
該模型的工作原理類似於 Avail 的 Nexus 互操作性層,其中包括證明聚合和排序拍賣機制,從而使其 DA 產品更加強大。與 Polygon 的 AggLayer 一樣,與 Avail 集成的每條鏈或 Rollup 都可以在 Avail 現有的生態系統內進行互操作。此外,Avail 池化了來自各種區塊鏈平臺和 Rollup 的有序交易數據,包括以太坊、所有以太坊 Rollup、Cosmos 鏈、Avail Rollup、Celestia Rollup 以及不同的混合結構,如 Validiums、Optimiums 和 Polkadot 平行鏈等。來自任何生態系統的开發人員都可以在使用 Avail Nexus 的同時在 Avail 的 DA 層之上進行無需許可的構建,Avail Nexus 可用於跨生態系統的證明聚合和消息傳遞。
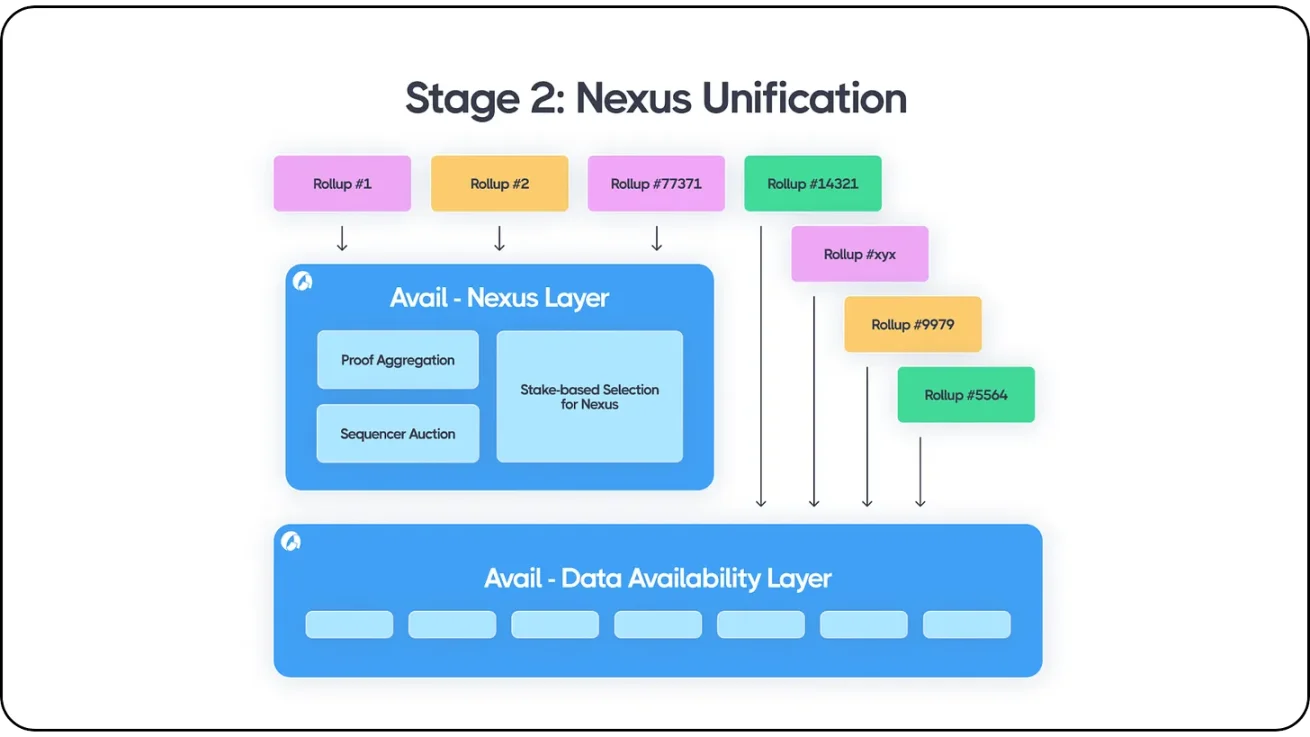
Avail Nexus
Nebra 專注於證明聚合和結算,它們可以在不同的證明系統之間進行聚合。例如,聚合 xyz 系統證明和 abc 系統證明,這樣你就有了 agg_xyzabc (而不是在證明系統內聚合,這樣你就有了 agg_xyz 和 agg_abc )。該架構使用 UniPlonK ,它標准化了電路系列的驗證者工作,使得跨不同 PlonK 電路驗證證明更加高效和可行。從本質上講,它使用零知識證明本身(遞歸 SNARK)來擴展驗證部分(通常是這些系統中的瓶頸)。對於客戶而言,「最後一英裏」結算變得更加容易,因為 Nebra 處理所有批量聚合和結算,團隊只需要更改 API 合約調用即可。
Astria 正在研究一些有趣的設計,圍繞他們的共享排序器如何與證明聚合一起工作。他們將執行部分留給 Rollup 本身,Rollup 在共享排序器的給定命名空間上運行執行層軟件,本質上只是「執行 API」,這是 Rollup 接受排序層數據的一種方式。他們還可以輕松地在此處添加對有效性證明的支持,以確保區塊沒有違反 EVM 狀態機規則。
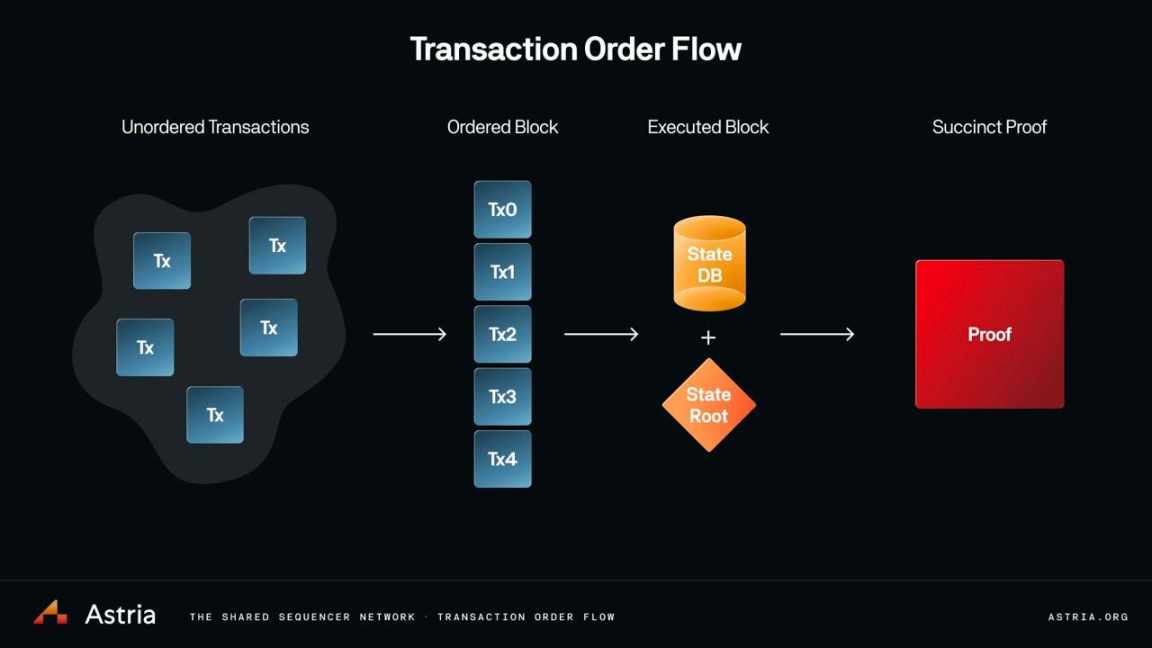
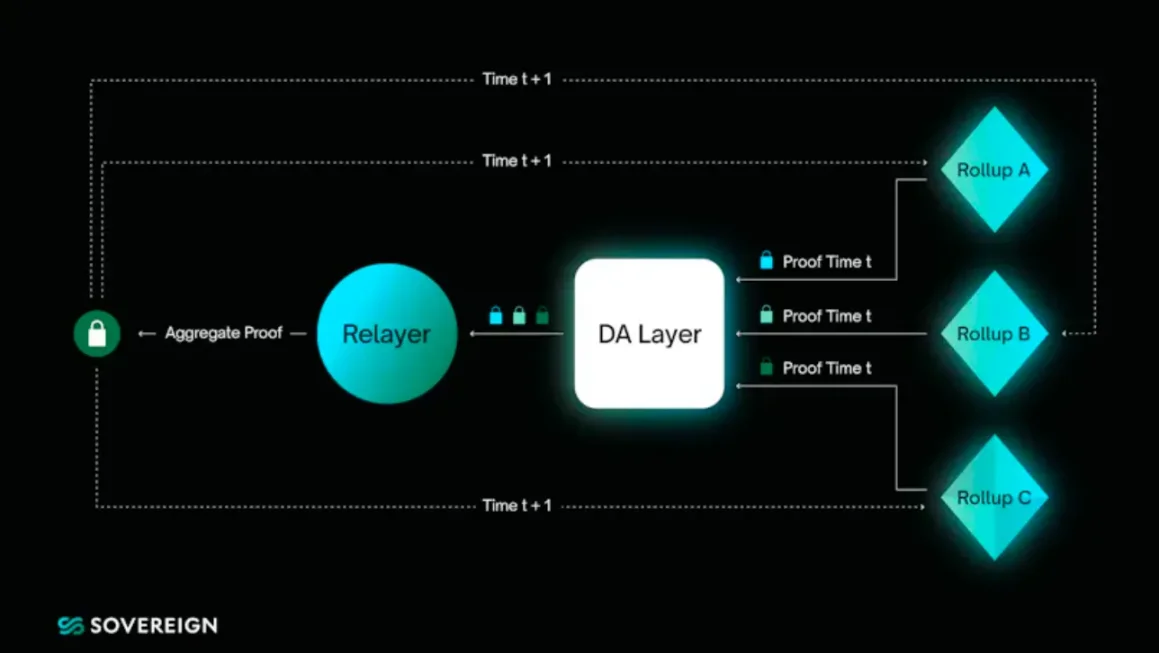
在這裏,像 Astria 這樣的產品充當 #1 → #2 流程(無序交易 → 有序區塊),執行層 /Rollup 節點是 #2 → #3 ,而像 Nebra 這樣的協議充當最後一英裏 #3 → #4 (執行區塊 → 簡潔證明)。Nebra 也可能是理論上的第五步,其中證明被聚合然後進行驗證。Sovereign Labs 也在研究與最後一步類似的概念,其中基於證明聚合的跨鏈橋是其架構的核心。
總體而言,一些應用層开始擁有底層基礎設施,部分原因是如果它們不控制底層堆棧,那么僅保留上層應用可能會帶來激勵問題和高昂的用戶採用成本。另一方面,隨着競爭和技術進步不斷壓低基礎設施成本,應用程序 / 應用鏈與模塊化組件集成的費用變得更加低廉。我相信這種動態會更加強大,至少目前如此。
有了所有這些創新(執行層、結算層、聚合層),更高的效率、更輕松的集成、更強的互操作性和更低的成本就變得可能了。所有這些最終會為用戶帶來更好的應用程序,為开發人員帶來更好的开發體驗。這是一個成功的組合,可以帶來更多的創新,以及更快的創新速度。
原文鏈接
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
星球日報
文章數量
8586粉絲數
0
評論