Sin7y技術解讀:交易並行執行
前言
本次調研對比了類似以太坊的實現系統,分析了交易並行執行的難點和可能性。鏈本身基於 Account 模型設計,而不是採用 UTXO 模型。
調研對象
1.國內的衆多聯盟鏈,如FISCO-BCOS,支持並行執行block內部的交易驗證。
2.Khipu,公鏈項目,以太坊協議的scala實現。
3.Aptos,公鏈項目,Move虛擬機。
交易並行執行的難點
我們先來回顧一下傳統的交易執行過程:
執行模塊從區塊中取出一個個交易,然後依次去執行。執行的過程中會修改最新的世界狀態,一筆交易執行完成後進行狀態累加,到達區塊完成後的最新的世界狀態。下一區塊的的執行時又嚴格依賴上一個區塊執行後的世界狀態,所以傳統的交易线性執行過程無法很好的進行並行執行優化。
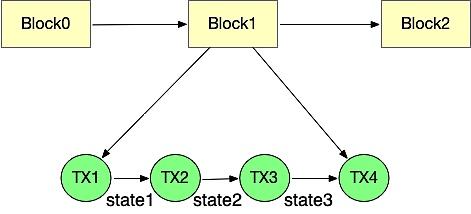
目前在以太坊的並行方案中,主要存在以下幾點衝突:
1.账戶衝突。如果兩個线程同時對一個地址账號的余額或者其他屬性進行處理,能否跟順序處理的結果保持一致,也就是世界狀態是否是一個確定的有限狀態機。
2.同一個地址Storage存儲衝突。兩個合約變量都對同一個全局變量進行了存儲修改。
3.跨合約調用衝突。本來合約Ar 先部署,合約B 需要等到合約A部署完成之後,去調用合約A ,但是當交易並行之後,並沒有這種先後順序,這就存在着衝突。
交易並行方案對比
FISCO-BCOS
概述
FISCO-BCOS 2.0 在處理交易的過程中運用了圖結構,設計了一種基於DAG模型的並行交易執行器(PTE,Parallel Transaction Executor)。PTE能充分發揮多核處理器優勢,使區塊中的交易能夠盡可能並行執行。同時對用戶提供簡單友好的編程接口,使用戶不必關心繁瑣的並行實現細節。基准測試程序的實驗結果表明,相較於傳統的串行交易執行方案,理想狀況下4核處理器上運行的PTE能夠實現約200%~300%的性能提升,且計算方面的提升跟核數成正比,核數越多性能越高。
方案細節
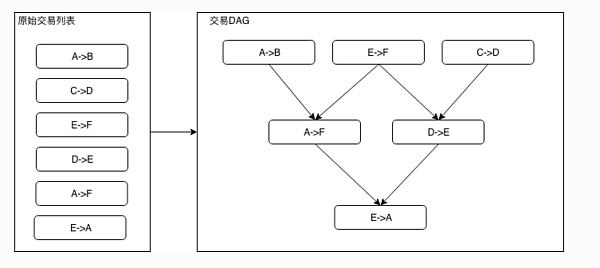
一個無環的有向圖被稱為有向無環圖(DAG)。在一批交易中,可以通過一定的方式識別出各個交易佔用的互斥資源,再根據交易在Block中的順序以及互斥資源的佔用關系構造出一個交易依賴的DAG圖。如下圖所示,凡是入度為0(無被依賴的前序任務)的交易均可以並行執行。基於左圖的原始交易列表的順序進行拓撲排序後,可以得到右圖的交易DAG。
模塊架構
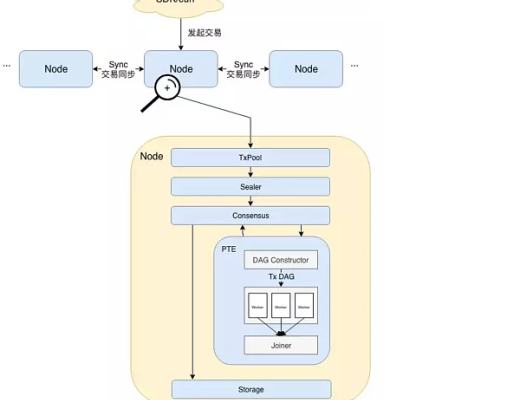
用戶直接或間接通過SDK發起交易。
隨後交易在節點間同步,擁有打包權的節點調用打包器(Sealer)從(TxPool)中取出一定量交易並將其打包成一個區塊。此後,區塊被發送至共識單元(Consensus)准備進行節點間共識。
達成共識前需要執行交易驗證,此處便是PTE工作的开始。從架構圖中可以看到,PTE首先按序讀取區塊中的交易,並輸入到DAG構造器(DAG Constructor)中。DAG構造器會根據每筆交易的依賴項,構造出一個包含所有交易的交易DAG,PTE隨後喚醒工作线程池,使用多個线程並行執行交易DAG。匯合器(Joiner)負責掛起主线程,直到工作线程池中所有线程將DAG執行完畢。此時Joiner負責根據各個交易對狀態的修改記錄計算state root及receipt root,並將執行結果返回至上層調用者。
區塊驗證通過後,區塊上鏈。在交易執行完成後,若各個節點狀態一致,則達成共識。區塊隨即寫入底層存儲(Storage),被永久記錄於區塊鏈上。
交易DAG構造流程
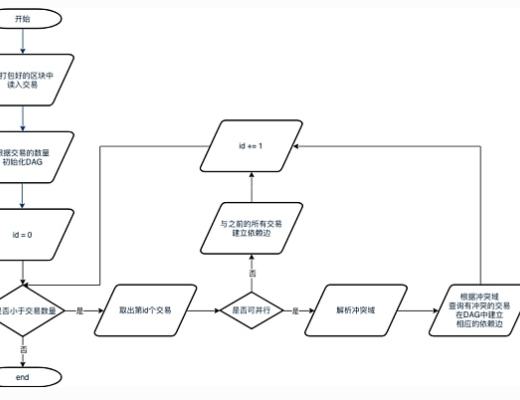
1.從打包好的區塊中取出區塊的所有交易。
2.將交易數量作為最大頂點數量初始化一個DAG實例。
3.按序讀出所有交易。如果一筆交易是可並行交易,則解析其衝突域,並檢查是否有之前的交易與該交易衝突。若存在衝突,則在相應交易間構造依賴邊。若該交易不可並行,則認為其必須在前序的所有交易都執行完後才能執行,因此在該交易與其所有前序交易間建立一條依賴邊。
備注:都建立依賴邊之後則無法並行,只能順序執行。
DAG執行流程
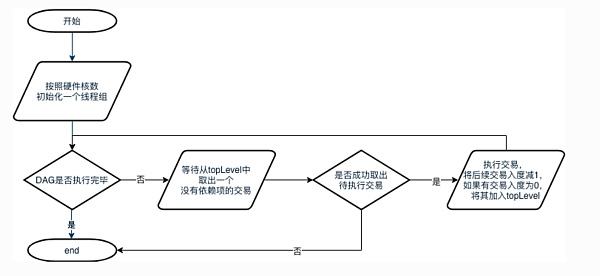
1.主线程會首先根據硬件核數初始化一個相應大小的线程組,若獲取硬件核數失敗,則不創建其他线程.
2.當DAG尚未執行完畢時,线程循環等待從DAG的waitPop方法以取出入度為0的就緒交易。若成功取出待執行的交易,則執行該交易,執行後將後續的依賴任務的入度減1。若有交易入度被減至0,則將該交易加入topLevel中。若失敗,則表示DAG已經執行完畢,线程退出。
問題與解決方法
1.對於同一個區塊,如何確保所有的節點執行完成,狀態一致(三個root 匹配)?
FISCO BCOS採用驗證state root、transaction root 和 receipt root三元組是否相等的方式來判斷狀態是否達成一致。transaction root是根據區塊內的所有交易計算出的一個哈希值,只要所有共識節點處理的區塊數據相同,transaction root必定相同。由於這一點比較容易保證,因此重點在於如何保證交易執行後生成的state和receipt root相同。
衆所周知,對於在不同CPU核心上並行執行的指令,指令間的執行順序無法提前預測。並行執行的交易也存在同樣的情況。在傳統的交易執行方案中,每執行一筆交易,state root便發生一次變遷,同時將變遷後的state root寫入交易回執中。所有交易執行完後,最終的state root就代表了當前區塊鏈的狀態,同時再根據所有交易回執計算出一個receipt root。
可以看出,在傳統的執行方案中,state root扮演着一個類似全局共享變量的角色。當交易被並行且亂序執行後,傳統計算state root的方式顯然不再適用。這是因為在不同的機器上,交易的執行順序一般不同,此時無法保證最後的state root的一致性。同理,receipt root的一致性也無法得到保證。
在FISCO BCOS中,先並行執行交易,將每筆交易對狀態的改變歷史記錄下來,待所有交易執行完後,再根據這些歷史記錄綜合計算出一個state root。由此就可以保證即使並行執行交易,最後共識節點仍然能夠達成一致。
2. 如何判定兩筆交易是否有依賴?
若兩筆交易本來無依賴關系但被判定為有,則會導致不必要的性能損失;反之,如果這兩筆交易會改寫同一個账戶的狀態卻被並行執行了,則該账戶最後的狀態可能是不確定的。因此,依賴關系的判定是影響性能甚至能決定區塊鏈能否正常工作的重要問題。
在簡單的轉账交易中,我們可以根據轉账的發送者和接受者的地址來判斷兩筆交易是否有依賴關系。
以如下3筆轉账交易為例:A→B,C→D,D→E。可以很容易看出,交易D→E依賴於交易C→D的結果,但是交易A→B和其他兩筆交易沒有聯系,因此可以並行執行。
這種分析在只支持簡單轉账的區塊鏈中是正確的。但因為我們無法准確知道用戶編寫的轉账合約中到底有什么操作,這種分析一旦放到圖靈完備、運行智能合約的區塊鏈中,則不夠准確。
可能出現的情況是:A→B的交易看似與C、D的账戶狀態無關,但是在用戶的底層實現中,A是特殊账戶,通過A账戶每轉出每一筆錢必須要先從C账戶中扣除一定手續費。在這種場景下,3筆交易均有關聯,則它們之間無法使用並行的方式執行。若還按照先前的依賴分析方法對交易進行劃分,則必定會出現問題。
那么我們能否做到根據用戶的合約內容自動推導出交易中實際存在哪些依賴項?答案是否定的。正如靜態分析中提到的,我們很難分析出合約依賴項以及執行過程。
FISCO BCOS將交易依賴關系的指定工作交給更熟悉合約內容的开發者。具體來講,交易依賴的互斥資源可以由一組字符串表示。FISCO BCOS暴露接口給到开發者,开發者以字符串形式定義交易依賴的資源,告知鏈上執行器,執行器則根據开發者指定的交易依賴項自動將區塊中的所有交易排列為交易DAG。比如在簡單轉账合約中,开發者僅需指定每筆轉账交易的依賴項是{發送者地址+接收者地址}。進一步講,假如开發者在轉账邏輯中引入了另一個第三方地址,那么依賴項就需要定義為{發送者地址+接受者地址+第三方地址}。
這種方式實現起來較為直觀簡單,也比較通用,適用於所有智能合約,但也相應增加了开發者肩上的責任。开發者在指定交易依賴項時必須十分小心,如果依賴項沒有寫正確,後果將無法預料。
並行框架合約
FISCO BCOS為了开發者能夠使用並行合約這一套框架設定了一些合約編寫的規範, 細節如下:
並行互斥
兩筆交易是否能被並行執行,依賴於這兩筆交易是否存在互斥。互斥是指兩筆交易各自操作合約存儲變量的集合存在交集。
例如,在轉账場景中,交易是用戶間的轉账操作。用transfer(X, Y) 表示從X用戶轉到Y用戶的轉账接口,則互斥情況如下:
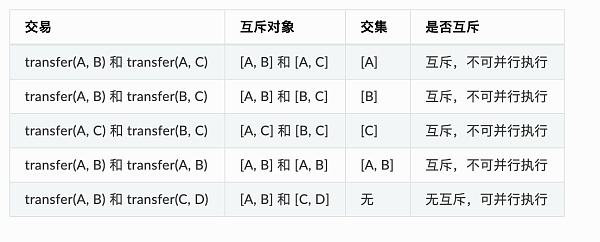
互斥參數:合約接口中,與合約存儲變量的“讀/寫”操作相關的參數。例如轉账接口為transfer(X, Y),X和Y都是互斥參數。
互斥對象:一筆交易中,根據互斥參數提取出來的、具體的互斥內容。例如轉账接口為transfer(X, Y),一筆調用此接口的交易中,具體的參數是transfer(A, B),則這筆操作的互斥對象是[A, B];另外一筆交易調用的參數是transfer(A, C),則這筆操作的互斥對象是[A, C]。
判斷同一時刻兩筆交易是否能並行執行,就是判斷兩筆交易的互斥對象是否有交集。相互之間交集為空的交易可並行執行。
FISCO-BCOS提供了兩種編寫並行合約的方式,一種是solidity 合約,另一種是預編譯合約。這裏只介紹solidity合約,預編譯合約同理。
solidity合約並行框架
編寫並行的solidity合約時,在基礎上只需要將 ParallelContract.sol 作為需要並行的合約的基類,並調用registerParallelFunction()方法,注冊可以並行的接口即可。
parallelContract 代碼如下:

以下是基於並行框架合約進行編寫的轉账合約:

確定接口是否可並行
可並行的合約接口,必須滿足:
無調用外部合約。
無調用其它函數接口。
確定互斥參數
在編寫接口前,需要先確定接口的互斥參數,接口的互斥即是對全局變量的互斥。互斥參數的確定規則為:
接口訪問了全局mapping,mapping的key是互斥參數。
接口訪問了全局數組,數組的下標是互斥參數。
接口訪問了簡單類型的全局變量,所有簡單類型的全局變量共用一個互斥參數,用不同的變量名作為互斥對象。
例如:合約裏有多個簡單類型的全局變量,不同接口訪問了不同的全局變量。如需將不同接口並行,則需要在修改了全局變量的接口參數中定義一個互斥參數,調用時指明使用了哪個全局變量。在調用時,主動給互斥參數傳遞相應修改的全局變量的“變量名”,用以標明此筆交易的互斥對象。如:setA(int x)函數中修改了全局參數globalA,則需要將setA函數定義為set(string aflag, int x), 在調用時,傳入setA("globalA", 10),用變量名“globalA”來指明此交易的互斥對象是globalA。
確定參數類型和順序
確定互斥參數後,根據規則確定參數類型和順序,規則為:
- 接口參數僅限:string、address、uint256、int256(未來會支持更多類型)。
- 互斥參數必須全部出現在接口參數中。
- 所有互斥參數排列在接口參數的最前。
可以看出,FISCO-BCOS交易並行其實很大程度依賴用戶編寫合約的規範。如果用戶編寫合約不規範,系統貿然的進行了並行執行,則有可能會造成账本root不一致的問題。
Khipu
概述
與FISCO-BCOS的觀點不同,Khipu認為讓用戶在編寫合約的時候識別和標明會發生靜態衝突的地址範圍並且不出錯是不現實的。
競態是否會出現、在何處出現、在什么條件下會出現,只有當確定性獲取涉及到當前狀態後才可以做判斷。以目前的合約編程語言而言,幾乎不可能通過對代碼進行靜態分析來獲取完全無誤並且沒有遺漏的結果。
Khipu針對這方面做了比較全面的嘗試,並且完成了工程實現。
方案細節
在Khipu的實現方案中,同一個區塊裏面的每條交易都從前一個區塊的世界狀態开始,然後並行執行,在執行過程中記錄下所有的理想經歷路徑上遇到的以上三種競態。在並行執行階段結束後,轉入合並階段。合並階段开始逐條合並並行的世界狀態,每合並一條交易時,先從記錄下來的靜態條件中判斷是否已經與前面已經合並的競態條件有衝突。如果沒有,直接合並。如果有,則將這條交易以之前已經合並的世界狀態為起點再執行一次。最後合並的世界狀態將用區塊的哈希做最後的校驗。這是最後的一道防线,如果校驗有誤,則放棄前面的並行方案,將區塊內的交易重新串行執行。
並行度指標
Khipu 在這裏引入了一個並行度指標,即一個區塊內能夠不需要再次執行就可以直接合並結果的交易比例。Khipu通過對以太坊從創世區塊到最新的區塊進行幾天的重放觀測發現,這個比例(並行度)平均可以達到80%。
總體而言,如果計算任務可以被完全並行化,單鏈的可擴展性就會是無限的,因為總是可以往一個節點裏添加更多的CPU核心數量。若事實並非如此,則最大的理論速率就受限於安達爾定理:
你能給系統進行提速的極限取決於那些不能進行並行化的部分的倒數。也就是說,如果你可以進行99%的並行化,那么你就可以提速到100倍。但如果你只能實現95%的並行化,那么你就只能提速到20倍。
在以太坊所有的交易重放下來看,大概有80%的交易是可以並行化的,有20%不能並行化,所以Khipu對以太坊提速的平均效率是5倍左右。
衝突標記
通過對evm代碼指令的解讀可以發現,衝突的地方是一些有限的指令對於stroage產生了讀寫過程,因此可以通過記錄這些讀寫的地方形成一個讀寫集合。僅僅利用靜態的代碼分析無法確保這些過程都被記錄,所以需要在處理每個區塊裏面的交易時對每一筆交易並行的預執行一次。通過預執行過程,可以得知這些交易是否是對同一個account或者storage進行讀寫,然後對每筆交易產生一個readSet和writeSet。簡言之,預執行的過程就是首先將世界狀態拷貝多份作為所有交易的初始狀態。假設區塊鏈裏面存在100個交易,那么這100多交易就可以通過线程池並行執行。每個合約都有同樣的初始世界狀態,執行過程中會也會產生100個readSet和writeSet ,同時也會各自產生100個新的狀態。
預執行結束後,开始下一個階段的處理。理想狀態下,如果這100個readSet和writeSet沒有衝突,那么就可以直接進行合並,產生這個區塊裏面所有交易執行完畢的最終世界狀態。但是交易往往不會如此理想化,所以正確的處理方式為:先取第一個交易執行後的狀態裏面的readSet、writeSet,和第二個合約執行後的readSet、writeSet進行對比,看他們是否有對同一個账戶或者storage進行讀寫。如果有,那就意味這兩筆交易存在衝突,則以第一個交易執行完成的狀態作為第二個交易的起始狀態,將交易二重新執行一遍。以此類推,隨着不斷進行合並狀態機,衝突集也會不斷地累加。只要後面的交易與前面的交易存在衝突就順序執行,直到執行完所有的交易。
通過對以太坊主網的交易重放可以發現,凡是衝突多的地方,大部分是交易所在同一個區塊進行的有互相關聯的交易,這也是與該過程相符合的。
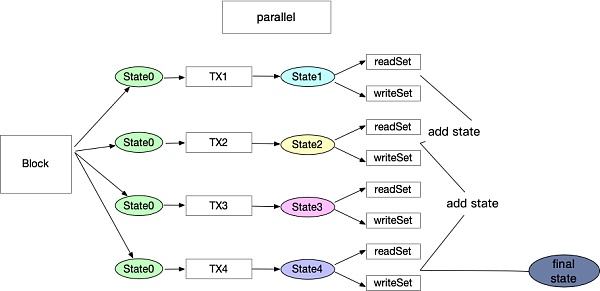
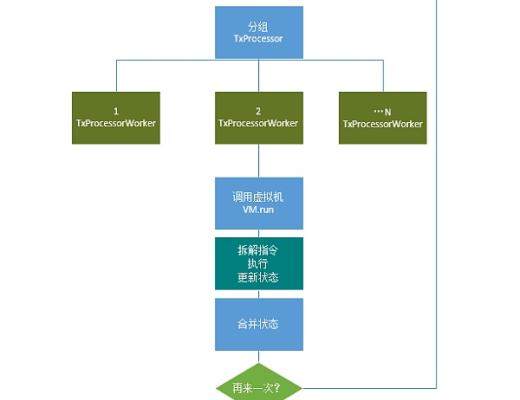
處理流程圖
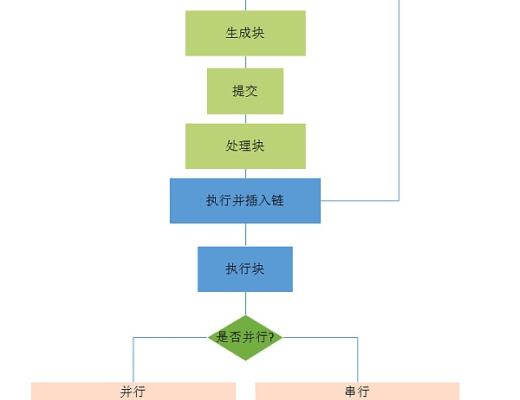
具體並行執行過程
Aptos
概述
Aptos在Diem的Move語言和MoveVM的基礎上創建了一個高吞吐量的鏈,實現了並行執行。Aptos 的方法是檢測關聯關系,同時對用戶/开發者透明。也就是說,不要求交易明確聲明它們使用哪一部分狀態(內存位置)。
方案細節
Aptos使用名為Block-STM的軟件交易內存 (Software transaction Memory ) 的修改版本,基於Block-STM 論文實現了並行執行引擎。
Block-STM使用MVCC(多版本並發控制)來避免寫-寫衝突。所有到相同位置的寫入都與它們的版本一起存儲,這些版本包含它們的tx-id 和寫入tx被重新執行的次數。當交易tx讀取某一個內存位置的值時,它從MVCC中獲得在tx之前出現的寫入該位置的值,以及關聯的版本, 從而判斷是否有讀寫衝突。在 Block-STM 中,交易在區塊內是預先排序的,並在執行期間在處理器线程之間劃分以並行執行。在並行執行中,假設沒有依賴關系執行交易,被交易修改的內存位置被記錄下來。執行後,驗證所有交易結果。在驗證期間,如果發現一個交易訪問了由先前交易修改的內存位置,則該交易無效。刷新交易的結果,重新執行交易。重復該過程,直到區塊中的所有交易都被執行。當使用多個處理器內核時,Block-STM 會加快執行速度。加速取決於交易之間的相互依賴程度。
可以看到,Aptos採用的方案和前文提到的Khipu大致類似,但是實現細節略有不同。主要區別如下:
Khipu對區塊內交易採用並行執行,順序驗證的方式,而Aptos 對區塊內的交易採用並行執行,並行驗證的方式。這兩種方案各有優缺點。Khipu的方案易實現,效率略低。Aptos的Block-STM實現採用了諸多线程中的同步與信號操作,難以進行代碼實現,但效率較高。
由於Move原生支持全局資源尋址,所以在利於並行執行的情況下,Aptos會對交易進行重新排序,甚至是跨區塊進行排序。官方宣稱這個方案既可以提高並行的效率,也可以解決MEV問題,但是這樣是否會影響用戶體驗則有待考慮。
Aptos在執行過程中會將執行得到的寫集存儲在內存中以獲得最大的執行速度,並將其用作要執行的下一個塊的緩存,任何重復的寫入操作都只需要寫入穩定的存儲器一次。
基准測試
Aptos針對Block-STM進行集成後做了相應的benchmark, 將10k交易一個區塊在順序執行情況下與並行執行情況下的表現進行了對比,結果如下:
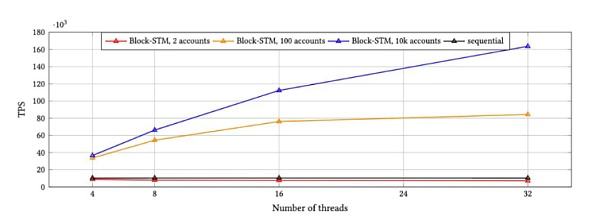
從上圖可以看到,Block STM在32個线程並行執行的情況下比使用程的順序執行實現了16倍的加速,而在高爭用情況下,Block-STM實現了超過8倍的加速。
總結
綜上所述,一些方案需要用戶在編寫合約時按照既定的規則寫存儲,這樣才能夠被靜態和動態分析發現依賴關系。Solana 和Sui採用了類似的方案,只是用戶感知度不同。這類方案本質上都是對於存儲模型的更改以獲得更好地分析結果。
Khipu和Aptos的方案屬於用戶無感知的。即用戶無需謹慎編寫合約,虛擬機會在執行前進行動態分析依賴關系,從而將沒有依賴關系的並行執行。這類方案實現難度較大,而且並行度在一定程度上取決於交易的账戶分部情況。當交易衝突較多的時候,不斷地重新執行反而會導致性能嚴重下降。Aptos在論文中提到後續可能也會對用戶編寫合約進行一些優化,從而更好地分析依賴關系,達到更快的執行速度。
單純的修改交易串行到並行模式在公鏈環境下可以帶來3~16倍的吞吐量提升。如果能夠結合大區塊和大的gas Limit等優化,L2吞吐量可以提升百倍左右。
考慮到工程實現和效率問題,OlaVM大概率會採用Khipu+定制化存儲模型方案。在獲得性能提升的同時,避免引入Block-STM帶來的復雜性,也便於後期更好的進行工程優化。
參考:
1.Block-STM 論文:[2203.06871] Block-STM: Scaling Blockchain Execution by Turning Ordering Curse to a Performance Blessing (arxiv.org)
2.FISCO-BCOS Github, FISCO-BCOS
3.Khipu Github, GitHub - khipu-io/khipu: An enterprise blockchain platform based on Ethereum
4.Aptos Github, GitHub - aptos-labs/aptos-core: Aptos is a layer 1 blockchain built to support the widespread use of of blockchain through better technology and user experience.
關於我們
Sin7y成立於2021年,由頂尖的區塊鏈开發者組成。我們既是項目孵化器也是區塊鏈技術研究團隊,探索EVM、Layer2、跨鏈、隱私計算、自主支付解決方案等最重要和最前沿的技術。團隊於2022年7月推出OlaVM白皮書,致力於打造首個快速、可擴展且兼容EVM的ZKVM。
微信公衆號:Sin7y
官網:https://sin7y.org/
白皮書:https://olavm.org/
社群:http://t.me/sin7y_labs
官推:@Sin7y_Labs
Github:Sin7y
研究文章(EN):https://hackmd.io/@sin7y
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
7月23:Mt. Gox 比特幣錢包在市場緊縮的情況下轉移了價值 28.2 億美元的 BTC
7月23:Mt. Gox 比特幣錢包在市場緊縮的情況下轉移了價值 28.2 億美元的 BTC一個引...
悅盈:比特幣68000的空完美落地反彈繼續看跌 以太坊破前高看回撤
一個人的自律中,藏着無限的可能性,你自律的程度,決定着你人生的高度。 人生沒有近路可走,但你走的每...