邁向大規模應用之路:使用Substrate實現基於存儲共識的鏈下計算範式
前言
一款大衆意義上成功的 Web2.0 To C 應用,至少應該在百萬月活量級。我們熟知的頂級的 Web2.0 應用 Twitter, Google, Facebook, WeChat, Tiktok 等,月活都在 10 億量級以上。也就是說,面向 C 端的應用,必需搞定高並發及大數據量存儲和檢索,以及其它一些東西。
而我們來看看目前基於區塊鏈的明星應用,截止目前(成文時:2021.10.15):
Audius,目前月活 400 萬用戶,號稱建立在以太坊和 Solana 之上,具體其使用鏈的方式,對區塊鏈的依賴有多大,信息並不透明
Axie Infinity,有 170 萬遊戲用戶,運行在其以太坊獨立鏈 Ronin 上,不過這個 Ronin 的信息同樣公开得較少
以太坊上的頭部 24 個DeFi 應用,用戶地址數加起來有 300 萬[1]
總體來說,區塊鏈上的用戶量量級處於一個較低狀態。
造成這種現狀,除了用戶本身關注度較少之外,還有兩個重要的基礎層面的原因:
1.現有的大部分 Dapp 的 UX 體驗,普通互聯網用戶難以理解和操作
2.現有區塊鏈的計算性能太低、數據存儲成本太高,使得使用成本太高
也就是說,現在這些區塊鏈(公鏈)的基礎設計,其實承載不了互聯網級別的用戶量,這裏面有結構性機制性的問題。
我們本篇嘗試討論如何才能讓區塊鏈適用於大規模應用場景。
月活百萬用戶應用的基本要求
我們這裏僅對 Web2.0 月活百萬用戶入門級應用稍作分析。
1.用戶 UX 要好用
Web App 和手機 App 的 UX 體驗要平滑,流程要順暢,前置要求不能過多(比如需要某個錢包账號,安裝某個瀏覽器插件),用戶上來就能用。並且账號不一定需要自己的重新注冊,能方便地使用現有的第三方登錄是最好的。
2.能支撐高並發,請求延遲要低
能支撐大量用戶的同時訪問,不能出現卡殼的情況,延遲也不能過高(超過數秒)。這些都會體現在產品的 UX 用戶體驗上面。面對大量的請求,不能出現服務崩潰,中斷的情況。
3.計算低成本
計算成本與計算性能這個指標是相關的,服務端系統的計算性能不能太低,不然無法承載高並發的請求。計算成本不能太高,不然雲服務器的成本會急劇攀升。
4.存儲低成本
用戶在使用 App 的過程中會產生大量的數據。這些數據不僅包含用戶直接創造的 UGC 數據,還有很多服務中間狀態數據,各個層級的日志數據。這些數據最後都會存儲下來,存放在 SQL 數據庫或、NoSQL 數據庫、對象存儲服務、或者文件存儲服務等等。一些索引服務如 ElasticSearch 也需要單獨存儲被索引的數據。這些存儲要佔用大量的存儲空間。考慮到數據的可靠性,還需要做冗余處理。做冗余處理,相當於數據佔用的空間要大幾倍。這些都要求存儲成本要保持比較低的水平,不然會導致服務整體的成本過高,App 難以運維下去。
Web3.0的要求
其實,Web3.0 的目標只有一個:开放性(Openness)。开放性是 Web3.0 的唯一核心目標。那么,开放性這個詞有哪些內涵呢?
1.數據的开放性
2.對數據的操作的开放性
3.組織形式的开放性
本文在這裏不打算展开論述,詳細討論可參見拙作:《對Web3.0概念的梳理》[2]和《為什么Web3.0需要區塊鏈》[3]。
目前區塊鏈計算方式的瓶頸
我們這裏討論一下主流區塊鏈以太坊 Ethereum 的技術方案存在主要問題。
1.合約虛擬機,分時復用,計算能力有限
全世界所有以太坊的節點都在 evm 中以單线程的形式運行一個合約序列。從合約程序的角度來看,每個對合約函數的調用按排隊執行,一個執行完再執行另一個,相當於分時復用同一個 CPU。這種計算模型,決定了節點的計算能力受限於節點單個 CPU 的計算能力,其性能限制非常大。目前以太坊的處理能力 TPS 為 13 左右。
2.存儲成本高昂
據計算,目前(發文時)在以太坊上每存儲 1k 字節數據的費用超過:$100(一次性付費)。而傳統雲存儲服務存儲 1 G 數據的成本大概是:$0.02 每月。如果按10年來算,以太坊上的存儲費用比雲存儲高 41,666,666 倍。
為了防止過度佔用計算資源和存儲資源,以太坊設計了 Gas 費機制。
擴容之路
由於以太坊的計算能力和存儲能力都非常有限,其它的公鏈項目便有了出頭的機會。不同的公鏈在不同的方向上做出了一定程度的創新。
Solana
Solana 思路是把 Layer1 性能做到最好,號稱目前 TPS 最高的公鏈。其 PoH 共識輔助機制,使得一些共識子流程可以使用 GPU 來做並行驗證。目前 Solana 的 TPS 大概在 2000 左右。
Solana 一定程度上放棄了部分去中心化特性,並且其節點配置要求特別高。這些都是追求高 TPS 的代價。
Ethereum 2.0,NEAR, Polkadot
這仨都是走的分片(Sharding)之路。分片非常難,可能是最難的擴容方案了。以太坊 2.0 節奏緩慢,遙遙無期。NEAR 據說 2021 年底發布 6 個分片的網絡,目前還不清楚分片後的網絡實際效果如何,帶來多大優勢,交易成本會不會增加。Polkadot 的平行鏈現在在穩步推進,其先行網已經上了幾個平行鏈了,但還沒經過真正應用的驗證。
分片的難,難在原理上,詳見 NEAR 的《夜影協議白皮書》[4]。現在尚無一個真正的穩定運行的分片網絡,分片網絡後面會不會遇到什么新的問題,是否具有實用性,這些都需要時間來驗證。
L2 群雄:Polygon, Arbitrum, Optimistic Rollup, ZK Rollup
L2 對以太坊的擴容是目前的主流擴容方向。詳見:《以太坊的Layer2擴容之路》[5]。
Cosmos, Octopus
這倆兄弟項目走的是多鏈跨鏈之路。基本出發點是認為支撐應用的最小單位是應用鏈(Appchain),而不是合約。每個應用一條鏈,然後所有應用鏈都可以通過 IBC 協議直接互聯互通。
上述提到的這些項目,到目前為止,都已產生可觀的影響。擴容之路不是那么容易,最後只能靠時間來檢驗,誰才能夠走到最後。
面向 Web3.0 應用的計算範式
前面提到,Web3.0 的核心在於开放性,而不是以下名詞中的任何一個(雖然每個都很重要):
安全性
區塊鏈
去中心化
密碼學
安全性是延伸屬性,密碼學和區塊鏈是工具,去中心化是手段,开放性才是目的(目標)。
而對區塊鏈來講,我們前面提到的所有主流的區塊鏈,其實都是面向資產而設計,而非應用。回顧歷史,如果從2008年比特幣誕生开始算起,這十多年,所有主流區塊鏈項目其實只做了一件事情:處理資產。12年的一個成果,剛剛好就是 2020 年之夏的 DeFi 熱潮。
即便只是資產這么一個東西,要處理好也是一件了不起的事情(試想想,全球的金融業本身就是一個特別大的產業)。也就是說,即使只處理資產、金融相關的業務,以太坊已經不夠用了,還要出現那么多的L2、側鏈、新型公鏈等項目來分擔處理。這么多選手一起上也還差得遠,離解決好金融業務這個目標還有太遠的距離。
也就是說,到目前為止,在區塊鏈上做的那些努力,連基本盤金融領域都尚未處理得過來,更遑論面向 Web3.0 進行應用這一層次的創新了。
鏈上邏輯只適合處理資產業務
在拙作《為什么區塊鏈需要 Web3.0》[6] 中提出:合約型公鏈僅適合於處理 DeFi(資產、金融)相關業務。而在本篇中,我們將進一步提出:所有鏈上邏輯都只適合處理 DeFi(資產、金融)相關業務。
既然本篇我們討論的是大規模的應用,那出發點就是大規模應用的標准,而不是做 Demo,演示其可能性。
對於合約型公鏈來說,可以把所有合約應用,組合起來看作一個大的應用,皆為鏈上邏輯。這是由基礎的账戶模型決定的。而對於由 Substrate 這種框架开發的應用鏈 Appchain 來說,其鏈上邏輯仍然只適合處理資產相關業務。區塊鏈的鏈上邏輯,無法用於處理通用型大規模的應用。理由如下:
1.鏈上邏輯的計算量受限於節點性能和出塊間隔的限制
2.鏈上邏輯必須在虛擬機體系內完成,不能有任何副作用
3.鏈上狀態的存儲使用 MPT 實現,具有一系列優異的特性(比如方便校對內容,方便做增量hash,方便訪問歷史版本),但是也增大了中間存儲量和計算量
4.鏈上數據結構受限於存儲特性和Gas費等,種類比較少,形式比較初級,要注意的細節點很多,在處理業務時很受限
5.由於區塊鏈的安全性要求(加密,編碼解碼),鏈上無法內置一個 SQL 這種 Web2.0 中最基礎而又強大的檢索引擎,這讓寫業務代碼的時候,需要人為手動在數據插入的時候建立更新索引對象,非常別扭
由於以上的這些問題,我們認為傳統的區塊鏈鏈上計算範式無法承載 Web3.0 應用的大規模實踐。面向 Web3.0 應用,我們需要尋找另外的計算和存儲範式。
基於 Arweave 的存儲共識範式
存儲共識範式(原名存儲計算範式):通過 Arweave 永久存儲和鏈下計算達到共識。
存儲共識範式是 everFinance 提出的下一代區塊鏈應用开發範式。在 Ethereum 模型中,計算會被區塊鏈網絡中的所有節點執行,所有節點都會生成和存儲全局狀態以供查詢。不同於 Ethereum 模型,存儲共識範式分離了計算和存儲,區塊鏈僅進行數據存儲不進行任何計算,所有計算由鏈下的客戶端/服務器執行,生成的狀態也由鏈下客戶端/服務器進行保存。
存儲共識範式使用了鏈下智能合約,智能合約可以是任何語言編寫的程序,這些程序的所有輸入參數都來自存儲型區塊鏈。在範式中,區塊鏈更像是計算機的硬盤,鏈下智能合約可以在任何具備計算能力的機器上進行。使用區塊鏈作為硬盤,所存儲的數據具備了不可篡改和可追溯的特性,區塊鏈為數據賦予了可信的特性。鏈下智能合約對可信數據進行計算,能保證狀態的最終一致性。
存儲共識範式开發的應用程序,具備區塊鏈的透明和可信特性,同時又具備傳統互聯網應用的高性能和可用性。存儲共識範式具備以下優勢:
1.可組合性:傳統金融服務間進行業務對接,需要會計對账,對账過程繁復且容易出錯。採用存儲共識範式,將金融交易記錄完全上鏈,把傳統金融服務轉化成區塊鏈應用,實現自動化對账,達到應用間的快速協同,高效組合。
2.开發門檻低:使用 Ethereum 虛擬機編寫智能合約需要使用 Solidity 語言,鏈下計算則可以用任何的語言進行开發,开發者可以將傳統的應用轉化成區塊鏈應用。
3.無性能限制:鏈下計算,其性能跟傳統應用一樣,鏈下服務器可以承載大量的交易。TPS 取決於提供服務的機器性能和構建應用的技術架構。
4.共識成本極低:100 萬筆交易僅需要 1 美金。
參考資料:Storage-based Consensus Paradigm[7]。
Substrate 框架的 OffChain 特性
OffChain 特性是 Substrate 中提供的一套相當強大的基礎設施。畢竟對區塊鏈來說,鏈上的邏輯操作空間非常有限,有些事情必須通過鏈下來完成。在沒有 OffChain Worker (OCW) 之前,這一類事情,通常是由預言機 Oracle 來完成。預言機是外部服務,通過區塊鏈節點 RPC 接口向區塊鏈提交交易從而把外界的信息傳到鏈上去。這種方式雖然是可行的,但它在安全性、集成性、可擴展性和基礎設施效率問題上面,仍然不夠好。
為了讓鏈下數據的集成更安全和有效,Substrate 提供了 offchain 相關的特性。其架構圖如下:
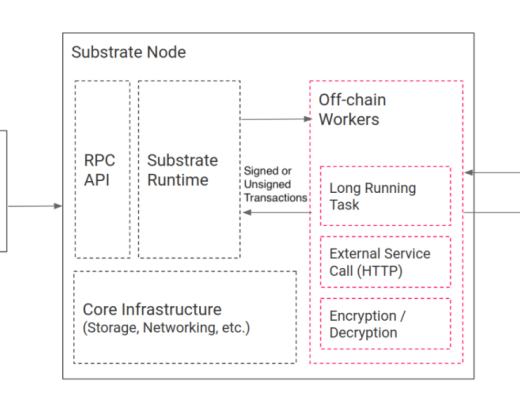
Off-chain Worker架構圖
Offchain 特性包含三大組件:
OffChain Worker
OffChain Storage
OffChain Indexing
OffChain Worker 用於實現鏈下邏輯。其代碼與 Runtime 代碼寫在一起,並被編譯到同一個 wasm 字節碼字符串中,在同一個交易中被傳播到全網絡。但是在執行的時候,OffChain Worker 的代碼是在獨立的 VM 中執行的,即與 Runtime 邏輯的執行完全隔離开。具體來說,OffChain Worker 能夠實現如下功能:
將計算的結果以交易形式提交到鏈上
包含一個全功能的 HTTP 客戶端,能夠訪問外部服務的數據
可以訪問本地 node 的 keystore,這樣便可以驗證和籤名交易
可以訪問本地的 KV 數據庫,且在所有 offchain worker 中共享這個數據庫
本地的安全的熵源,用來產生隨機數
可以訪問本節點的本地時間
可以 sleep 和 resume 工作
OffChain Storage 是鏈下邏輯獨立的存儲空間,與鏈上的 Storage 是完全隔離开的。它具有如下特性:
能被 OffChain Worker 讀取和寫入
存儲在 node 本地,不會傳遞到網絡中其它節點去,不會參與網絡共識
被所有同時運行的 OffChain Workers 共享訪問(因此需要鎖操作)。因此,可以利用其在不同的 Workers 之間通信
能被 Runtime 代碼寫入,但是不能讀。因此,可基於其實現一定的鏈上鏈下交互功能
可被 wasm 環境外的 node 中的代碼讀取,因此能被 RPC 讀取
OffChain Indexing 提供了在 Runtime 環境中,向 OffChain Storage 寫入數據的能力。但是不能讀取 OffChain Storage 中的數據。這為一些新的編程範式提供了可能性。
其它還有一些,比如,完善的OCW集成測試框架等等。
Substrate 的 OffChain 特性非常強大,令人印象深刻。
基於 Substrate 實現鏈基於存儲共識的鏈下計算範式
從 Arweave 存儲共識範式獲得靈感,我們來看看在 Substrate 中如何實現類似基於存儲共識的鏈下計算範式。
整個 Substrate 框架其實分成三大塊可編程邏輯:
1.Runtime
2.Offchain Worker
3.Node容器
和兩大塊存儲:
1.Runtime Storage 鏈上狀態存儲
2.Offchain Storage 鏈下存儲
詳情見下圖:
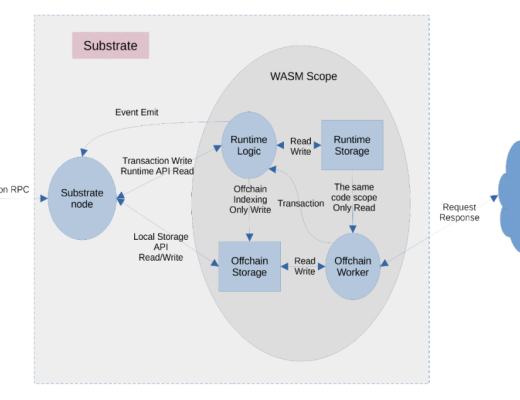
Substrate應用开發架構
前面我們說過,Substrate 中的 Runtime 只適合處理資產類邏輯,Runtime Storage 只適合存儲資產類數據,它們不適合處理和存儲其它大規模應用的邏輯和數據。
在《為什么Web3.0需要區塊鏈》中,有一幅 Web3.0 應用的通用架構圖:
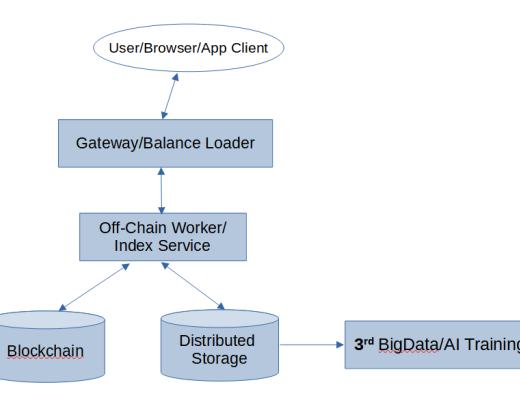
Web3.0 App 架構
可以看到,在 Web3.0 應用中,鏈下計算和鏈下存儲佔據非常重要的位置。在本節,可以將這幅圖針對 Substrate 做一細化,設計一套嶄新的計算模式。
我們理解:區塊(Block)是應用的操作和輸入數據的歷史分段打包(注意,不是歷史狀態的打包)。其與數據庫的SQL日志是類似的,區別在於:
1.分段打包,離散化,郵戳化
2.每一個分段都由多個節點參與共識確認,形成一個全網的共識,並在各自節點中敲定(finalized)。敲定的過程,也是對每個節點中的交易池中的交易定序的過程
每個塊頭包含三個Hash:
1.前面一個塊的 Hash,以明確當前塊是鏈到哪個塊上的(每個塊都有一個父塊,因此形成鏈狀,所以叫區塊鏈)
2.當前塊中包含的交易序列的總Hash, merkle_root。用於驗證,防止在網絡傳輸途中被篡改交易
3.當前節點中,全局鏈上狀態空間的 state_root。用於不同節點間全局狀態空間的同步,每一個塊都校驗 state_root,能讓所有參與節點內部保持一個嚴格的同步的一致的鏈上全局狀態。
基於這些認識,我們可以基於前面的 Substrate 應用架構圖,做出如下設計:
將邏輯從 Runtime 中剝離。Runtime 邏輯的作用僅在於:
1.作為代理函數,將外部交易的調用的方法的名稱和輸入數據按一定規範寫入 Offchain Storage (使用前面提到的 offchain indexing 特性)
2.校驗輸入參數
3.用於升級整個 wasm 代碼(其中包含應用的主要邏輯所在的 offchain worker 代碼)。這個機制內建在 substrate runtime 中,不需要單獨开發
而鏈上存儲不再需要了(但不是 0,Substrate默認有一些,這個我們不需要關心)。
真正的邏輯在 Offchain Worker 中執行。這部分代碼是 wasm 字節碼,由鏈上發交易統一管理升級,保證所有節點的一致性。Offchain Worker 代碼在塊導入時執行。執行邏輯如下:
1.Offchain worker 入口函數執行
2.檢查 offchain storage 中是否有符合某些鍵值對規範的存儲內容,這個內容應該包括:方法名稱,參數表(入參數據)。如果有,取出方法名稱和參數表(可能是序列化後的)
3.在 Offchain worker 中,按方法名稱進行路由,並把反序列化後的參數表傳到對應的路由 handler 中去。這些路由 handler 代碼可以寫在不同的文件中,在 runtime 主文件中引進來(同樣會被編譯到 wasm 中)
4.Handler 可以使用 offchain storage 中的數據,充分完成計算、聚合、重整化等工作
5.Handler 執行完成後,可以通過以下方式通知網關要返回的結果:
a.通過 offchain worker 中的 http 請求能力,主動將結果發送給 gateway,gateway 監聽到結果後,根據結果中的 uri 對應地將數據返回給前端
b.將結果緩存在 offchain storage 中。gateway 定時輪詢或監聽 substrate node 的 rpc 接口,通過 rpc 接口從 offchain storage 中取得相應結果,並返回給前端
6.主流程結束。
以上就是使用 Substrate 實現基於存儲共識的鏈下計算範式的主要流程。這裏需要解釋一下為什么這種方式就是基於存儲共識的鏈下計算:
1.執行邏輯 offchain worker 中的代碼,是通過 substrate 交易提交到鏈上,通過 p2p 網絡,在各個節點通過驗證後,更新到各個節點上的。這保證了執行代碼的一致性(起到了 Arweave 對應的作用)
2.Substrate offchain indexing 的一大特性就是:一致性。Substrate.dev[8] 中有一段話:”Unlike OCWs, which are not executed during initial blockchain synchronization, off-chain indexing is populating the storage every time a block is processed, so the data is always consistent and will be exactly the same for every node with indexing enabled.”。有這個特性保證,就可以保證存儲在 offchain storage 中的對方法的調用和傳入的參數在所有節點上是一致的。也即是保證了輸入數據的一致性(起到了 Arweave 對應的作用)
3.一旦 Offchain worker 开始執行,其是在鏈下執行的,與鏈上邏輯和存儲完全分开。這也就對應了 Arweave 存儲共識範式中的鏈下執行部分
4.計算後的結果,並不會重新上鏈(因為並不需要鏈上存儲),這是非常重要的一點。在這方面,與 Arweave 存儲共識範式也是相同的。
好了,我們說了這么多,到底 使用 Substrate 實現基於存儲共識的鏈下計算範式有什么優勢值得我們關注呢?下面一節,我們重點與目前已有的典型計算方案做一下對比。
與目前典型計算方案的對比
與傳統區塊鏈計算範式的對比
這裏,我們說傳統區塊鏈計算範式,指的就是鏈上計算範式。
Substrate 基於存儲共識的鏈下計算範式的優勢:
1.Offchain worker 計算不再受限於出塊間隔的要求,可以實現長時間的計算或等待
2.Offchain worker 是獨立的輕量級线程,同時可並發執行多個輕量級线程,以充分利用節點的計算能力
3.Offchain worker 具有訪問外部服務的能力,也具有對外部產生副作用的能力,這點在實際的業務中,非常重要
4.Offchain Storage,不再受鏈上設計制約,可以充分利用已有的數據庫領域的歷史積累和前沿創新,為大規模數據存儲鋪平道路
5.Offchain Storage 中的存儲內容,可以分為三個部分。只有方法名調用和輸入數據這塊需要保持強一致性。邏輯運算結果需要訪問(界面)一致性。在第三部分可以靈活地存取/緩存本地節點數據,以實現更靈活地編程
6.用於 Substrate 鏈下計算的節點可以是整個區塊鏈大網絡節點中的一部分,這樣可有效控制計算成本和存儲成本,使得內容的處理和存儲量級可以大規模的擴張
Substrate 基於存儲共識的鏈下計算範式的劣勢:
1.Substrate Storage 目前是簡單的 kv 數據庫,失去了 MPT 結構天生的一些特性(如:方便的歷史版本訪問,快速的增量hash,快速比對等)
2.鏈上存儲狀態在每一個區塊中都有 state_root 做同步,而 Substrate 鏈下計算範式則失去了這個特性。這樣對存儲狀態的同步缺少強制性
3.Substrate 鏈下計算範式對計算結果的存儲和中間狀態的存儲需要有一套自定義的規範,這些規範只是定義在 offchain worker 代碼中,而沒有其它節點強制驗證的過程
4.在 Substrate worker 中仍然要注意,諸如隨機數和外部請求這些副作用,不能對需要一致性的存儲區造成影響。因此在編寫代碼的時候,需要人為注意,需要有約定或者最佳實踐
與基於 Arweave 的存儲共識範式的對比
Substrate 鏈下計算範式的優勢:
1.鏈的集成度更高。Substrate節點本身組成一條區塊鏈,不再單獨需要一條鏈作為服務
2.Substrate 鏈的交易的驗證過程比 Arweave 數據上傳請求驗證過程更細致。Substrate Runtime 中可以寫交易的自定義驗證代碼,這是在鏈上執行的,而 Arweave 只是鏈上存儲服務,做不到這一點
3.Substrate offchain indexing 是從鏈上主動往鏈下寫內容,而 Arweave 需要鏈下的計算客戶端主動從 Arweave 網絡上去拉對應的數據。這個過程顯得不那么自動化,至少輪詢的次數會多。另外,從 Arweave 上拉數據存在網絡訪問,可能存在網絡訪問失敗的問題,如果數據量較大,那么下載完成也需要可觀的時間。而 Substrate offchain indexing 完全運行在一個節點內部,性能更好,集成度也更高,對开發者來說,掌控力更好
4.基於 Substrate 節點,鏈上邏輯和鏈下邏輯是統一運維的,集成度更好,運維的可靠性更好(去信任,減少扯皮可能性)
5.Substrate 鏈下邏輯強制使用 wasm 字節碼來運行。在這點上,Arweave 並沒有要求。Webassembly 是一套得到國際廣泛支持的字節碼標准,在其上有非常多的創新,生態在快速發展。從運行效率和未來生態來說,採用 wasm 來部署應用是一個優勢
簡單來說,Substrate 基於存儲共識的鏈下計算範式,相當於實現了 Arweave 的一部分功能,但是沒有提供 Arweave 永存的特性。這點上,如果將 Substrate 鏈的塊歷史上傳到 Arweave 上存儲,那么就充分地利用了 Arweave 的永存優勢。
Substrate 鏈下計算範式的劣勢:
1.語言中不立。Substrate 目前只能使用 Rust 語言進行开發,這意味着要使用 Substrate 實現 Web3.0 應用开發,必須學習使用 Rust語言。而 Arweave 存儲共識範式是語言中立的,可以用任何語言开發
2.Substrate 鏈下計算範式對編程方式有新要求,而基於 Arweave 存儲共識範式的編程开發就與 Web2.0 开發類似,只需要調用 Arweave 相關的第三方服務即可
3.Arweave 實現的永存,對需要一致性共識的內容(代碼和輸入)具有歷史可靠性更好的優勢。即使區塊鏈項目倒閉了,它的那些內容還可以從 Arweave 上查到(意義大家可以討論)
4.Arweave作為一個存儲計算服務,類似於 XaaS(X as a Service),在某些場景下會很方便
我們前面描述過,Substrate 鏈下計算範式需要人為做一些約定,在這點上,Arweave 存儲共識範式一樣會遇到。這點上兩者一致。
與 The Graph/SubQuery 的對比
Substrate 是工具套件(像當年的 LAMP 一樣),The Graph/SubQuery 是服務。The Graph/SubQuery 是外部索引服務,主要用於對鏈上拋出的事件進行索引,並通過寫 Mapping 方法實現事件信息提取,生成 schema 結構化數據存入數據庫中。它們提供 GraphQL接口,其內部本身也還是傳統的 SQL 或 NoSQL 數據庫。
Substrate 基於存儲共識的鏈下計算範式的優勢:
1.集成度更高,The Graph/SubQuery 需要一個第三方外部服務才能獲取數據
2.Substrate 的模式能提供的接口形式更靈活。在網關上配置 RPC,Restful, GraphQL 都可以
3.Substrate 更可控,更去中心化。The Graph/SubQuery 是一個服務,大家都用這個服務,對這個服務的依賴性也就更強,對其運行的穩定性也就有擔憂。而 Substrate 這套工具,只需要對自己的鏈負責,別人出的問題不會影響到自己,自己出的問題不會影響別人。大家部署自己獨立的服務,其實是更好的執行去中心化的過程(前提是盡量用同一套工具,或至少用遵循同一套協議的工具)
Substrate 基於存儲共識的鏈下計算範式的劣勢:
1.目前將 Offchain Storage 替換/升級 成支持 SQL 引擎的存儲還沒實現,索引還得自己來維護
2.The Graph 能夠對合約公鏈進行索引(用於开發 Dapp),而 Substrate 鏈下計算範式只適用於 Substrate 框架實現的 Appchain
3.The Graph/SubQuery 是對鏈上拋出的信息進行索引,鏈上寫代碼的方式該怎樣就怎樣,不受影響,也即沒有侵入式。而 Substrate 鏈下計算範式對使用 Substrate 框架开發代碼的方式有要求,要按照新的範式來寫代碼,所以是侵入式的(雖然本文認為新的計算範式更適用於 Web3.0 應用)
對比可見,兩者各有其適用的場景。The Graph/SubQuery 更適用於傳統的基於合約的 Dapp 开發,Substrate 基於存儲共識的鏈下計算範式更適用於面向具體場景的 Web3.0 App 的开發。
與傳統中心化應用的對比
由於鏈下計算的特性,傳統中心化應用的那些成熟的基礎設施(比如分布式數據庫),理論上來說都能被 Substrate 基於存儲共識的鏈下計算範式應用所利用。
Substrate 基於存儲共識的鏈下計算範式的優勢:
1.相對於傳統中心化應用來說,Substrate 的鏈下計算範式應用是去中心化應用,業務邏輯在各個節點上運行,並且通過區塊鏈的強制特性保持了業務和運行結果的一致性。去中心化應用的一切優勢,Substrate 鏈下計算範式的應用都自動具有
2.保障了开放性。前文提到的三個層次(數據,數據的操作,組織的形式)的开放性,在這個計算範式下,都能得到有效保證,這正是我們 Web3.0 追求的目標。任何一個感興趣的人都可以運行 Substrate 節點,同步所有歷史區塊,跑出所有數據來。獲取數據的人不一定要參與鏈的共識。而傳統的中心化應用,在這三個層次上,都是封閉的
Substrate 基於存儲共識的鏈下計算範式的劣勢:
1.同樣的邏輯,需要在各個鏈下計算節點重復計算,並在每個節點都做存儲。這在計算成本和能耗上,確實不是優勢。但是由於參與鏈下計算的節點數量可以控制,這塊的冗余性與傳統中心化應用需要做的數據冗余和邏輯冗余(以防止一個節點的服務導致的服務中斷),其實是類似的
2.在基礎設施層面,中心化應用能用到充分成熟的支撐大規模應用的基礎設施,而 Substrate 鏈下計算範式的基礎設施還不成熟
目前 Substrate Offchain 基礎設施的不足
Offchain Storage 目前只是最基礎的 kv 數據庫實現(rocksdb)。要支撐真正面向實際的應用,基礎設施還需要完善,有幾個方向可以參考:
1.Redis:Redis作為內存KV數據庫,其內建豐富的數據結構的支持,使得其得到了各種領域大規模的應用
2.Mongodb:Mongodb作為對象型數據庫,特別適合某些領域
3.Tikv + Tidb:作為新一代分布式數據庫的代表,tikv 在 rocksdb 之上做了分布式協議層,而 tidb 進一步在 tikv 之上做了 SQL 引擎層。這是非常有效合理的層次劃分,這種理念也特別適合用在 Substrate Offchain Storage 未來的改進上面。如果能夠嫁接 tikv/tidb 到 Substrate 中來,那么 tikv/tidb 上面的很多生態設施都可以一並用到 Substrate 的鏈下計算上來,非常美好的局面
另外就是代碼編寫的思維有些變化:Offchain Worker 是定時器思維,或流編程思維。與傳統的服務器的 on_request/response 思維有不同。這塊兒如何最佳實踐,還需要更多研究。
對 Web3.0 App 的定義
基於本篇前面章節的討論,我們可以將區塊鏈進一步做如下區分:用於處理鏈上資產的鏈,我們叫它 資產鏈(Asset Chain)。用於處理 Web3.0 應用數據的使用鏈下計算範式的鏈,我們叫它 數據鏈(Dataset Chain)。基於這種區分,我們可以做出如下示意圖:
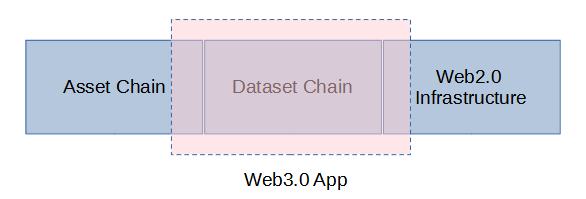
這個圖定義了:
Web3.0 App = Dataset Chain + Asset Chain 的一部分 + 一部分Web2.0已有的基礎設施
數據鏈(Dataset Chain)是 Web3.0 App 的核心載體。基於存儲共識的鏈下計算範式實現的 Web3.0 App,其位置處於區塊鏈大生態的邊界,一邊連接資產區塊鏈,一邊連接已有的 Web2.0 基礎設施。
工具 or 服務?
在本文快要結束的時候,我們來簡單做一下關於工具還是服務的思辨。這裏的服務,指的是 To B 基礎設施層面的服務,而不是 To C 業務型的服務。
通常,你要完成一件事情,有兩個選擇:
1.使用一個工具(從某個網站下載,或者別人給你的),在自己的電腦上運行計算,完成
2.使用一個服務(通常是通過一個瀏覽器頁面),在服務所在的服務器上運行計算,然後將結果返回給你
這就是工具與服務的區別:計算,是在你自己的地盤內完成,還是在第三方的地盤上完成。
雲服務 IaaS 取得巨大的成功。從以前的自己买服務器托管至機房的模式,到雲服務 IaaS,开啓了雲時代,進而到現在的 k8s,這條路目前還看不到盡頭。
而相對於 IaaS,更上層的 PaaS 似乎並不成功。反而 SaaS 取得了一定的成功。
服務的產生總是滯後的,开始總是先用一些工具(开發框架)進行實踐。我們不要忘了,开啓了 Web2.0 時代的是什么?是 LAMP(Linux 操作系統,Apache 網頁服務器,MariaDB 或 MySQL 數據庫,PHP、Perl 或 Python 腳本語言)。而到目前為止,全世界仍然有 30% 的網站由 Wordpress (一個 PHP 建站程序)搭建(更多數據可查看這裏[9])。
而 Java Spring 框架、Ruby on Rails 以及 Nodejs 等技術棧框架,在整個互聯網(Web2.0)的發展過程中,起到了相當重要的作用。這些框架給了你:
1.在本地开發調試部署一個完整應用(Web, App)的流程和能力
2.對你自己的代碼邏輯有 100% 的掌控力
3.在自己申請的雲服務器(集群)上運行,自己對應用數據有 100% 的掌控力
4.對互聯網服務的運行成本可以有比較准確的預估
5.其它等等
這些框架沒給你:
1.隨着業務的擴展,需要自己維護服務器集群
2.需要自己維護服務器安全
3.其它等等
而第三方服務給了你:
1.現成的功能組件,低成本的开箱即用
2.完全無需關注運維的問題,需要的所有擴容都是自動完成的
3.快速的試驗環境
4.其它等等
第三方服務沒給你:
1.透明的實現
2.准確的計算成本(如果不是免費的話,免費的正式使用顧慮感會更強)
3.深入自定義優化的空間
4.其它等等
對於創業團隊來講,有些場景下力求短平快的服務啓動,會傾向於直接使用第三方服務實現。而當業務規模擴張到一定階段的時候,力求對各個組件的運行實現全面掌控,這時就傾向於用开發框架的配套組件自己來搭建服務了。當然實際情況是往往混搭起來使用。
如果考慮文化、地域、國家政策等更多因素,具有自主搭建的能力的需求就更加強烈。
最關鍵的一點是,各方能夠自己比較容易地搭建相對完整的的服務,對於 “去中心化” 的實現,是一個非常重要的措施。如果所有人都在用同一個服務,這個服務是不是另一種層面的中心化(不管這個服務的實現本身是中心化的還是去中心化的)?
除非特別專業性的服務,一般來說,服務是可選項,开發框架(工具)才是根本立足點。
不應忽視對开發框架的投資。
結語
本文我們嘗試為 Web3.0 App 設計了一種面向大規模應用的技術路线:基於存儲共識的鏈下計算範式。本文使用 Substrate 框架作為示例來講解。理論上來說,任何框架都可以實現此計算範式——只有集成度、成熟度的區別。大家可以嘗試將此計算範式引入到自己的框架中實踐。
本文由 Mike Tang 和 Outprog 合作完成。
參考資料
[1]: https://cryptobriefing.com/ethereum-defi-ecosystem-has-hit-3m-users/
[2]: https://mp.weixin.qq.com/s/vJM6TIZT2f-tnQ49cpMnrw
[3]: https://mp.weixin.qq.com/s/h76lTnFWlvpXs72aBVs3FA
[4]: https://near.org/papers/nightshade/
[5]: https://www.theblockbeats.com/news/24443
[6]: https://mp.weixin.qq.com/s/zXqJ0BGdEbvZypAwLWKmtQ
[7]: https://mirror.xyz/0xDc19464589c1cfdD10AEdcC1d09336622b282652/KCYNKCIhFvTZ1DmD7IpXr3p8di31ecC283HgMDqasmU
[8]: https://substrate.dev/docs/en/knowledgebase/learn-substrate/off-chain-features#off-chain-indexing
[9]: https://techjury.net/blog/percentage-of-wordpress-websites/#gref
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
7月23:Mt. Gox 比特幣錢包在市場緊縮的情況下轉移了價值 28.2 億美元的 BTC
7月23:Mt. Gox 比特幣錢包在市場緊縮的情況下轉移了價值 28.2 億美元的 BTC一個引...
悅盈:比特幣68000的空完美落地反彈繼續看跌 以太坊破前高看回撤
一個人的自律中,藏着無限的可能性,你自律的程度,決定着你人生的高度。 人生沒有近路可走,但你走的每...
評論