解讀Bittensor:一月上漲400%,AI+Crypto賽道黑馬
原文作者:Knower
原文編譯:Luffy,Foresight News
相關動態:
TAO(Bittensor)流通市值突破 15 億美元,已躋身加密貨幣市值前五十

朋友們,好久不見了。我希望你們所有人都能享受到加密貨幣領域最近一些積極的價格走勢。為了獲得豐厚的回報,我決定編寫一份關於人工智能加密項目 Bittensor 的正式報告。我不是加密貨幣方面的專家,所以你可能會認為我對人工智能不太熟悉。然而實際上,我在加密貨幣之外花費了大量空闲時間進行人工智能研究,並且在過去 3-4 個月中一直在熟悉人工智能領域的重要更新、進步和現有基礎設施。
盡管有一些措辭並不准確且缺乏分析性的推文,但我還是要澄清事實。閱讀完本文內容後,你對 Bittensor 的了解將遠遠超過預期。這是一份篇幅有點長的報告,我並不是故意堆砌詞句,這很大程度上是因為大量的圖片和截圖。 請不要將文章輸入 ChatGPT 來獲取摘要,我在這些內容上投入了大量時間,你無法以這種方式了解整個故事。
當我撰寫這份報告時,一位朋友(他恰好是一個 Crypto Twitter KOL)告訴我,「人工智能 + 加密貨幣 = 金融的未來」 。在你閱讀本文時,請時刻牢記這一點。

人工智能是加密技術开始統治世界的最後一塊拼圖,還是只是實現我們目標的一小步?答案要靠你自己去尋找,我只是提供一些值得深思的東西。
背景信息
用 Bittensor 的話說,Bittensor 本質上是一種用於編寫衆多去中心化商品市場或位於統一代幣系統下的「子網絡」的語言,其目標是將數字市場力量引導到社會最重要的數字商品——人工智能。
Bittensor 的使命是建立一個去中心化網絡,通過獨特的激勵機制和先進的子網絡架構,能夠與以前「只有像 OpenAI 這樣的巨頭公司才能實現的」模型相競爭。最好將 Bittensor 想象成一個由互操作部件組成的完整系統,一臺借助區塊鏈構建的機器,以更好地促進人工智能功能在鏈上的普及。
管理 Bittensor 網絡有兩個關鍵參與者,他們是礦工和驗證者。礦工是向網絡提交預先訓練的模型以換取獎勵份額的個人。驗證器負責確認這些模型輸出的有效性和准確性,並選擇最准確的輸出返回給用戶。例如,Bittensor 用戶請求 AI 聊天機器人回答涉及衍生品或歷史事實的簡單問題,無論當前在 Bittensor 網絡中運行多少個節點,這個問題都會得到回答。
用戶與 Bittensor 網絡交互的步驟簡單描述如下:用戶向驗證器發送查詢,驗證器將其傳播給礦工,然後驗證器將礦工輸出進行排名,排名最高的礦工輸出將被發送回給用戶。
這一切都非常簡單。
通過激勵,模型通常提供最佳輸出,Bittensor 創建了一個積極的反饋循環,礦工之間相互競爭,引入更精細、更准確和更高性能的模型,以獲取更大份額的 TAO(Bittensor 生態代幣)並促進更積極的用戶體驗。
要成為驗證者,用戶必須成為 TAO 的前 64 位持有者之一,並在 Bittensor 的任何子網絡(提供訪問各種形式人工智能的獨立經濟市場)上注冊了 UID。例如,子網 1 專注於通過文本提示進行標記預測,子網 5 則專注於圖像生成。這兩個子網可能使用不同的模型,因為它們的任務截然不同,並且可能需要不同的參數、精度以及其他特定功能。
Bittensor 架構的另一個關鍵方面是 Yuma Consensus 機制,類似於在整個子網網絡中分配 Bittensor 可用資源的 CPU。 Yuma 被描述為 PoW 和 PoS 的混合體,具有在鏈下傳輸和促進情報的附加功能。雖然 Yuma 支撐着 Bittensor 的大部分網絡,但子網絡可以選擇加入或不依賴 Yuma 共識。具體細節復雜而模糊,而且有各種各樣的子網和相應的 Github,所以如果你只想大致了解的話,知道 Yuma 共識的自上而下的方法就可以了。

但是模型呢?
與普遍看法相反,Bittensor 並不自己訓練模型。這是一個極其昂貴的過程,只有較大的人工智能實驗室或研究組織才能負擔得起,並且可能需要很長時間。我試圖對 Bittensor 中是否包含模型訓練做出絕對回答,但我唯一的發現並不是結論性的。

去中心化訓練機制有點拗口,但其實也不難理解。 Bittensor 驗證器的任務是「在 Falcon Refined Web 6 T 代幣未標記數據集上進行評估礦工生成的模型的連續遊戲」,以根據兩個標准(時間戳和相對於其他模型的損失)對每個礦工進行評分。損失函數是一個機器學習術語,用於描述某種類型的模擬中預測值與實際值之間的差異,代表給定輸入數據和模型輸出的錯誤或不准確程度。
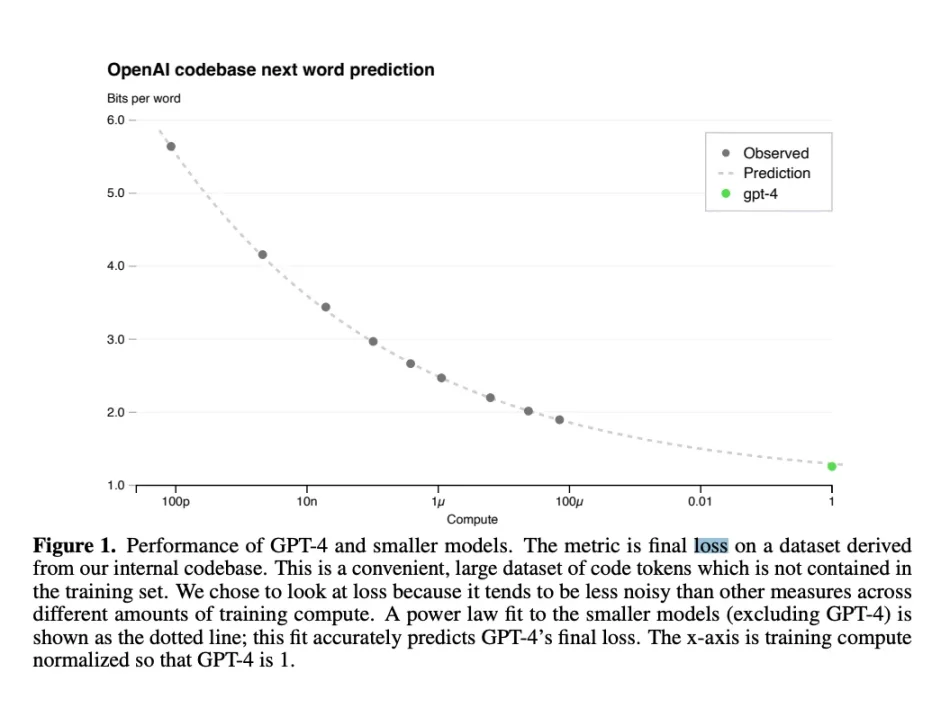
關於損失函數,這是我昨天從 Discord 中獲取的 sn 9 (相關子網絡)的最新表現,請記住,最低損失並不一定意味着平均損失:
「如果 Bittensor 本身不訓練模型,它還能做什么嗎?!」
事實上,大型語言模型(LLM)的「創建」過程分為三個關鍵階段,分別是訓練、 微調和情境學習(加入一點推理)。
在我們繼續進行一些基本定義之前,先看一下 紅杉資本 2023 年 6 月關於 LLM 報告 ,他們的調查結果為:「通常除了使用 LLM API 之外, 15% 的公司從頭开始或以开源庫為基礎構建了自定義語言模型。定制模型訓練比幾個月前顯着增加。這需要自己的計算堆棧、模型中心、托管、訓練框架、實驗跟蹤等,這些都來自 Hugging Face、Replicate、Foundry、Tecton、Weights & Biases、PyTorch、Scale 等深受喜愛的公司。」
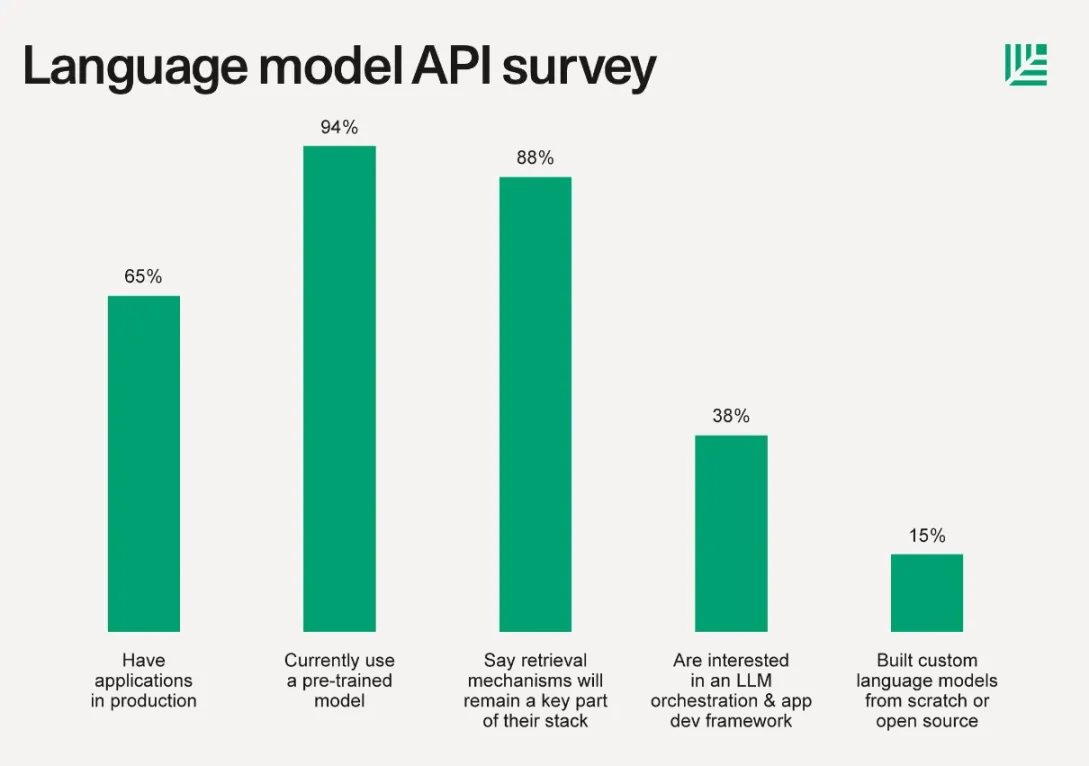
從頭开始構建模型是一項艱巨的任務, 85% 的受訪創始人和團隊不愿意進行這項工作。當大多數初創公司和獨立开發人員只想在外部應用程序或基於軟件的服務中利用大語言模型時,自托管的、跟蹤結果、創建或導入復雜的培訓場景和各種其他任務的工作量就太大了。對於人工智能行業 99% 的人來說,創造出與 GPT-4 或 Llama 2 相媲美的東西是不可行的。
這就是為什么像 Hugging Face 這樣的平臺如此受歡迎,因為你可以在他們的網站下載已經過訓練的模型,這個過程對於人工智能行業的人來說非常熟悉和常見。
微調更加困難,但適合那些希望提供特定利基領域的基於大語言模型的應用程序或服務的人。這可能是一家法律服務初創公司开發的聊天機器人,其模型根據各種律師特定的數據和示例進行了微調,或者是一家生物技術初創公司正在开發一個模型,該模型專門根據可能存在的生物技術相關信息進行了微調。

無論目的如何,微調都是為了進一步將個性或專業知識融入你的模型中,使其更適合和更准確地執行任務。雖然不可否認它很有用且更可定制,但每個人都認為它很困難,甚至 a16z 也這么 認為 :

盡管 Bittensor 實際上並未訓練模型,但向網絡提交自己模型的礦工聲稱以某種形式對模型進行微調,盡管這些信息不向公衆公开(或至少很難驗證)。礦工將其模型結構和功能保密以保護其競爭優勢,盡管有些是可以訪問的。
我們舉一個簡單的例子:如果你正在參加一項獎金為 100 萬美元的競賽,每個人都在競爭誰擁有表現最好的 LLM,如果你的所有競爭對手都在使用 GPT-2 ,你是否會透露你正在使用 GPT-4 ?雖然事實情況比這個例子所解釋的要復雜,但也並沒有多大區別。礦工根據其輸出准確度獲得獎勵,這比微調模型較少或平均性能較差的模型的礦工具有優勢。
我之前提到過情境學習,這可能是我將介紹的非 Bittensor 信息的最後一部分,但情境學習是一個廣泛定義的過程,用於引導語言模型獲得更理想的輸出。推理是模型在評估輸入時不斷經歷的過程,其訓練結果可能會影響輸出標記的准確性。雖然培訓成本高昂,但只有在模型准備好達到團隊在創建模型過程中指定的培訓級別時才會進行培訓。推理總是在發生,並且使用各種附加服務來促進推理過程。
Bittensor 現狀
了解背景知識後,我將探討有關 Bittensor 子網性能、當前功能以及未來計劃的一些細節。說實話,很難找到關於這個主題的高質量文章。幸運的是,Bittensor 社區成員給我發了一些信息,但即便如此,形成意見也需要做很多工作。我潛伏在他們的 Discord 中尋找答案,在這個過程中我意識到我已經成為會員大約一個月了,但沒有查看過任何頻道(我從不使用 Discord,更多的是 Telegram 和 Slack)。
不管怎樣,我決定看看 Bittensor 最初的愿景是什么,我在之前的報告中發現了以下內容:

我將在接下來的幾段中介紹它,但可復合的理論並不成立。對這個主題的研究已經有了一些,之前的截圖來自將 Bittensor 網絡定義為稀疏混合模型(這一概念是一篇 2017 年研究 論文 提出的)的相同報告。
Bittensor 有很多子網絡,足以讓我覺得有必要在本報告中專門為它們准備整個一小節篇幅。不管你相信與否,盡管這些對於網絡的實用性至關重要並支撐所有技術,但 Bittensor 的網站上沒有專門的部分來介紹這些以及它們的運作方式。我甚至在 Twitter 上詢問了一下,但似乎子網絡的奧祕只有那些在 Discord 中闲逛幾個小時並自行學習每個子網絡操作的人才能了解。盡管擺在我面前的任務艱巨,我還是做一了些工作。
子網 1 (通常縮寫為 sn 1)是 Bittensor 網絡中最大的子網,負責文本生成服務。在 sn 1 的前 10 名驗證者中(我對其他子網使用相同的前 10 名排名),大約有 400 萬個 TAO 質押,其次是 sn 5 (負責圖像生成),它有大約 385 萬個 TAO 質押。順便說一下,所有這些數據都可以在 TaoStats 上找到。
多模態子網絡 (sn 4) 擁有約 340 萬個 TAO,s n3(數據抓取)擁有約 340 萬個 TAO,sn 2 (多模態)擁有約 370 萬個 TAO。另一個最近增長迅速的子網絡是 sn 11 ,負責文本訓練,與 sn 1 的 TAO 質押數量相近。
就礦工和驗證者活動而言,sn 1 也是絕對領先者,擁有超過 40/128 名活躍驗證者和 991/1024 名活躍礦工。 Sn 11 實際上擁有所有子網中最多的礦工,有 2017/2048 個。下圖描述了過去一個半月的子網注冊成本:
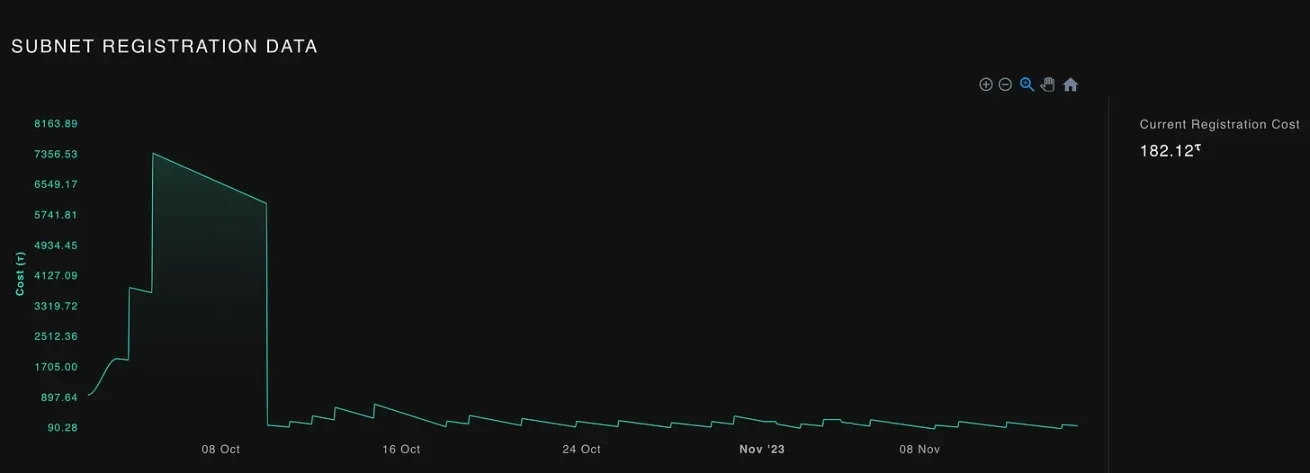
目前注冊一個子網的成本為 182.12 TAO,這個數字比 10 月份 7, 800 TAO 的峯值顯着下降,盡管我不完全確定這個數字是否准確。無論如何,隨着超過 22 個注冊子網絡以及 Bittensor 日益受到關注,我們很可能會在適當的時候看到更多的子網絡被注冊。其中一些子網絡似乎需要一段時間才能獲得關注。
就其他子網絡而言,sn 9 是一個很酷的子網絡,專門用於訓練:

以下是對 Bittensor 抓取子網 的說明:

子網絡模型非常獨特,是一種機器學習研究中稱為專家混合(MoE)的常見技術的示例,在這個過程中,模型被分成多個部分並提供單獨的標記,而不是被分配一整個任務。這對我來說很有趣,因為 Bittensor 不是一個統一的模型,實際上是一個模型網絡,這些模型以半隨機的方式進行查詢。 BitAPI 就是此流程的一個示例,它是一種基於 sn 1 構建的產品,可對入站用戶查詢的前 10 個礦工進行隨機抽樣。雖然任何給定子網絡中可能有數十甚至數百名礦工,但表現最好的模型會獲得更多獎勵。
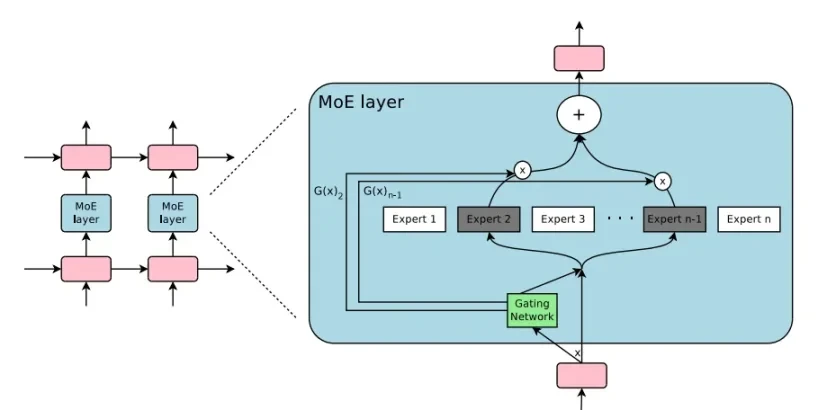
目前將多個模型組合或復合多個模型以增加或「堆疊」功能並不可行,這不是大語言模型的工作方式。我嘗試與社區成員進行推理,但我認為重要的是要注意,就目前情況而言,Bittensor 不是一個統一模型集合的示例,只是具有不同功能的模型網絡。
有些人將 Bittensor 與可訪問 ML 模型的鏈上預言機進行了比較。 Bittensor 將區塊鏈的核心邏輯與子網絡的驗證分开,在鏈外運行模型,以適應更多的數據和更高的計算成本,從而實現更強大的模型。你可能還記得,鏈上完成的唯一過程是推理。請參閱下面的 內容 了解 Bittensor 的解釋:

我認為社區中的很多人都過於專注於試圖讓每個人相信 Bittensor 將改變世界,而實際上他們只是在努力改變人工智能和加密貨幣交互的方式方面取得了進展。他們不太可能將礦工上傳模型的整個網絡改造為一臺極其智能的超級計算機——這不是機器學習的工作原理。即使是性能最好、成本最高的可用模型,距離實現通用人工智能 (AGI) 的定義還需要數年時間。
隨着機器學習社區不斷迭代和新功能的實現,AGI 的定義往往會有所不同,但基本思想是 AGI 能夠完全像人類一樣推理、思考和學習。其中的核心難題來自這樣一個事實:科學家將人類歸類為具有意識和自由意志的生物,而這在人類身上很難量化,更不用說強大的神經網絡系統了。
就目前而言,子網絡是分解與基於人工智能的應用程序相關的各種任務的獨特方式,社區和團隊有責任吸引希望利用 Bittensor 網絡這些核心功能的構建者。
這裏還值得補充的是,Bittensor 在加密貨幣之外的機器學習領域非常高效。 Opentensor 和 Cerebras 早在今年 7 月就發布了 BTLM-3 b-8 k 开源 LLM。從那時起,BTLM 在 Hugging Face 上的下載量已超過 16, 000 次,並獲得了非常積極的評價。
有人表示,由於 BTLM 的輕量級架構,BTLM-3 b 在與 Mistral-7 b 和 MPT-30 b 相同的類別中排名靠前,成為「每個 VRAM 的最佳型號」。下面是來自同一條推文的圖表,列出了模型及其數據可訪問性分類,BTLM-3 b 獲得了不錯的評分:
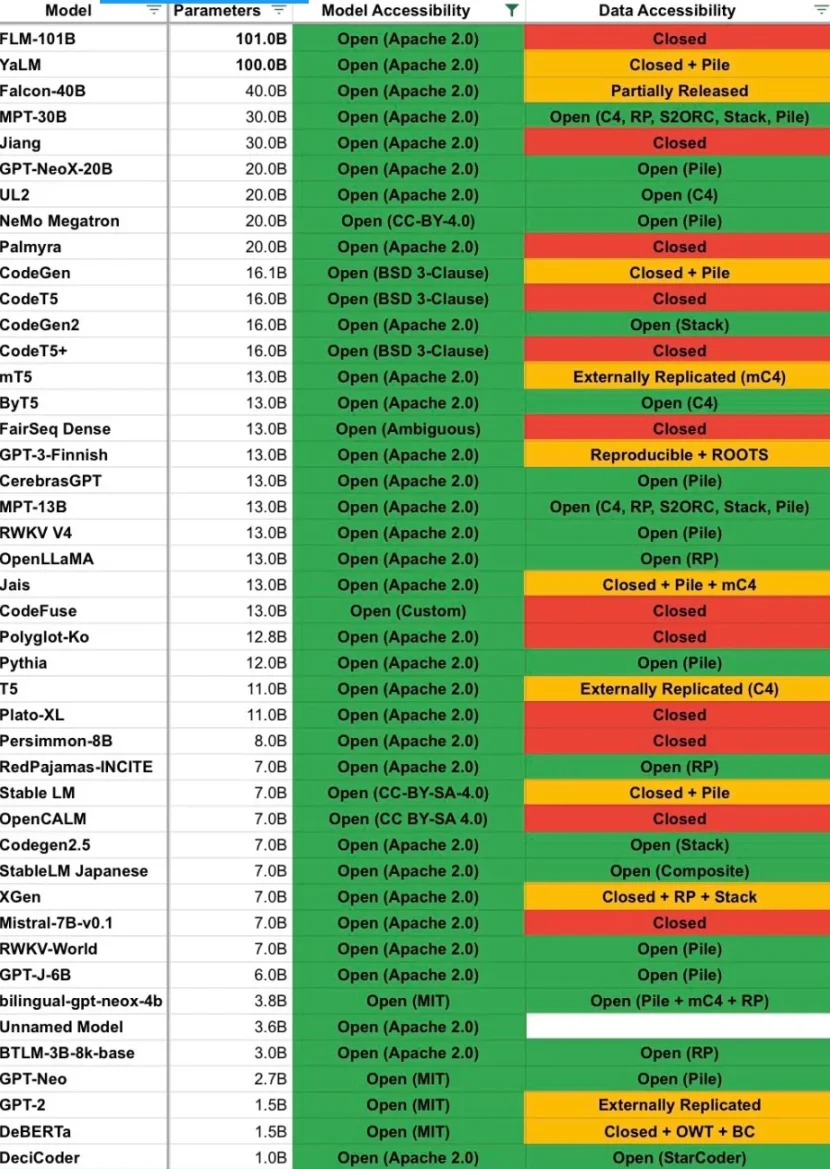
我在 Twitter 上說過 Bittensor 沒有做任何事情來加速人工智能研究,所以我認為我在這裏承認自己的錯誤是唯一正確的。此外,我聽說 BTLM-3 b 在某些情況下用於驗證,因為它價格便宜且在大多數硬件上運行速度快。
TAO 的用途
別擔心,我沒有忘記代幣。
Bittensor 大量借鑑了比特幣的靈感,同時也借鑑了 OG 教科書的玩法,融入了非常相似的代幣經濟結構,即最多 2100 萬個 TAO 和每 1050 萬個區塊減半的機制。截至撰寫本文時,流通的 TAO 數量約為 560 萬個,市值近 8 億美元。 TAO 的分配被認為是極其公平的,這份 Bittensor 報告 指出早期支持者沒有收到任何代幣,盡管很難驗證真假,但我們相信我們的消息來源。
TAO 既是 Bittensor 網絡的獎勵代幣,也是 Bittensor 網絡的訪問代幣,TAO 持有者能夠進行質押、參與治理或使用他們的 TAO 在 Bittensor 網絡上構建應用程序。每 12 秒鑄造 1 個 TAO,新鑄造的代幣將平均分配給礦工和驗證者。
在我看來,TAO 的代幣經濟學很容易設想一個通過減半減少釋放量導致礦工之間競爭加劇的世界,自然會產生更高質量的模型和更好的整體用戶體驗。然而,這裏還存在一個問題,即較少的獎勵會產生相反的效果,並且不會吸引激烈的競爭,而是會導致部署的模型或競爭的礦工數量停滯不前。
我可以繼續談論 TAO 的代幣效用、價格前景和增長動力,但前面提到的報告在這方面做得相當好。大多數 Crypto Twitter 已經確定 Bittensor 和 TAO 背後有一個非常可靠的敘述,目前我增加的任何內容都無法進一步錦上添花。從外部角度來看,我想說這些都是相當合理的代幣經濟學,沒有什么不尋常的。不過我還是應該提到,目前購买 TAO 非常困難,因為它尚未在大多數交易所上线。這種情況可能會在 1-2 個月內發生變化,如果幣安不盡快上线 TAO,我會感到非常驚訝。
前景
我絕對是 Bittensor 的粉絲,並希望他們能夠實現自己的大膽使命。正如該團隊在 Bittensor Paradigm 文章 中所說,比特幣和以太坊是革命性的,因為它們實現了金融獲取的民主化,並使完全無需許可的數字市場的理念成為現實。 Bittensor 也不例外,其目標是在龐大的智能網絡中實現人工智能模型的民主化。盡管有我的支持,但很明顯他們距離他們想要實現的目標還很遠,這對於大多數用加密貨幣構建的項目來說都是如此。這是一場馬拉松,而不是短跑。
如果 Bittensor 想要保持領先地位,他們需要繼續推動礦工之間的友好競爭和創新,同時擴展稀疏混合模型架構、MoE 構想以及以去中心化方式復合智能的概念的可能性。獨自完成所有這些工作已經夠困難的了,將加密技術納入其中會使其更具挑战性。
Bittensor 未來的道路還很漫長。盡管最近幾周圍繞 TAO 的討論有所增加,但我認為大多數加密社區並沒有完全意識到 Bittensor 當前的工作原理。有一些明顯的問題沒有簡單的解決方案,其中一些是:a) 是否可以實現高質量大規模推理,b) 吸引用戶的問題和 c)追求復合大語言模型的目標是否有意義。
不管你是否相信,支持去中心化貨幣的敘述實際上是一個相當大的挑战,盡管 ETF 的傳言讓這一切變得容易一些。
建立一個由智能的模型組成的去中心化網絡,這些模型可以相互迭代和學習,聽起來好得令人難以置信,部分原因是事實確實如此。在當前的背景窗口和大語言模型的限制下,不可能有一個模型能夠一遍又一遍地自我改進,直到達到與 AGI 的程度,即使是最好的模型也仍然是有限的。盡管如此,我認為將 Bittensor 構建為一個具有新穎的經濟激勵和內置可組合性的去中心化 LLM 托管平臺不僅僅是積極的,它實際上是目前加密領域最酷的實驗之一。
將經濟激勵融入人工智能系統面臨着挑战,Bittensor 表示,如果礦工或驗證者試圖以任何形式對系統進行博弈,他們將根據具體情況調整激勵機制。以下是今年 6 月的示例,代幣釋放量減少了 90% :

這在區塊鏈系統中是完全可以預料到的,所以我們不要假裝比特幣或以太坊在其整個生命周期中 100% 都是完美的。
對於局外人來說,加密貨幣的採用歷來都是難以下咽的藥丸,而人工智能也同樣存在爭議,甚至更具爭議性。將兩者結合起來會給任何人帶來維持用戶增長和活躍的挑战,這需要一些時間。如果 Bittensor 最終能夠實現復合大語言模型的目標,這可能是一件意義非凡的事情。
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
下周必關注|對等關稅將於4月9日生效;3月CPI數據即將公布(4.7-4.13)
下周重點預告 4 月 9 日 白宮高級官員:基准關稅稅率將於 4 月 5 日凌晨生效,對等關稅將於...
HashWhale BTC礦業周報 | 新關稅政策衝擊比特幣市場,礦工利潤空間受擠壓(3.29-4.04)
1、比特幣市場 在 2025 年 3 月 29 日至 4 月 4 日期間,比特幣具體走勢如下: 3...
東方HashKey Chain ,西方Base:合規趨勢下的TradFi之战
2025 年 1 月 Coinbase 和 EY-Parthenon 對 352 名機構決策者進行...
星球日報
文章數量
8830粉絲數
0
評論