SignalPlus:自動編碼器 (autoencoder)
原文作者:Steven Wang

前言
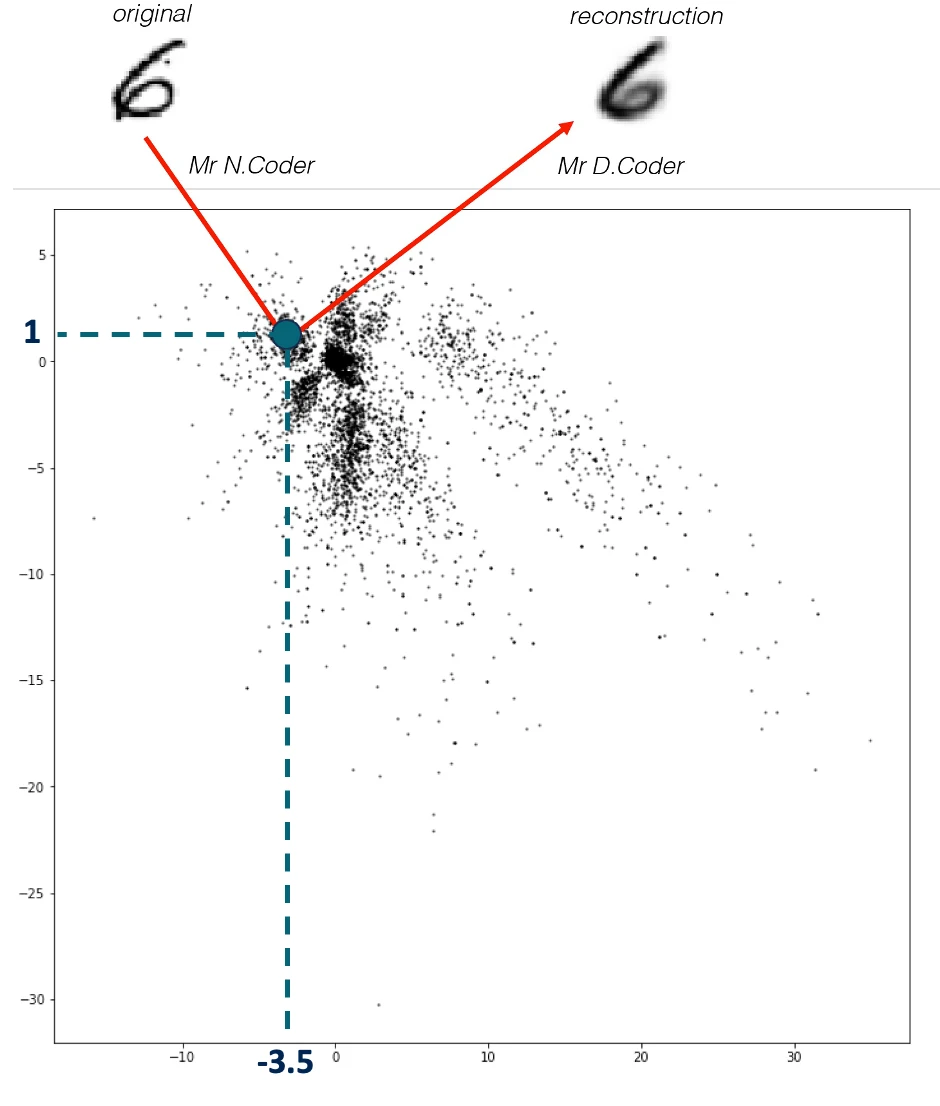
兩兄弟 N.Coder 和 D.Coder 經營着一家藝術畫廊。一周末,他們舉辦了一場特別奇怪的展覽,因為它只有一面牆,沒有實體藝術品。當他們收到一幅新畫時,N.Coder 在牆上選擇一個點作為標記來代表這幅畫,然後扔掉原來的藝術品。當顧客要求觀看這幅畫時,D.Coder 嘗試僅使用牆上相關標記的坐標來重新創作這件藝術品。
展牆如下圖所示,每個黑點是 N.Coder 放置的一個標記,代表一幅畫。在牆上坐標 [– 3.5, 1 ] 處的那幅原圖 (original) 數字 6 的畫 N.Coder 對其進行了重建 (reconstruction)。
下圖展示了更多例子,頂行的數字是原圖,中行的坐標是 N.Coder 將圖掛在牆上的坐標,底行是 D.Coder 根據坐標重建的作品。

問題來了,N.Coder 如何決定每幅畫在展牆上對應的坐標,而使得 D.Coder 僅用它就能重建原圖的?原來是兩兄弟在放置標記和重建作品的過程中,仔細監控售票處因顧客因重建質量不佳而要求退款而造成的收入損失,他們經過多年的“訓練”逐漸“精通”標記放置和作品重建,而最大限度地減少這種收入損失。從上圖對比原圖和重建可以看出,兩兄弟之間的磨合效果還不錯。來參觀藝術品的顧客很少抱怨 D.Coder 重新創作的畫作與他們來參觀的原始作品有很大的不同。
有一天,N.Coder 望着展牆,有了一個大膽的想法,對於那些牆上當前沒有標記的部分,如果讓 D.Coder 來重建能創作出什么樣的作品?如果成功的話,那么他們就可以舉辦自己 100% 原創的畫展了。想想就興奮,於是 D.Coder 隨機選取了之前沒有標記的坐標 ( 紅點 ) 來重建,結果如下圖所示。
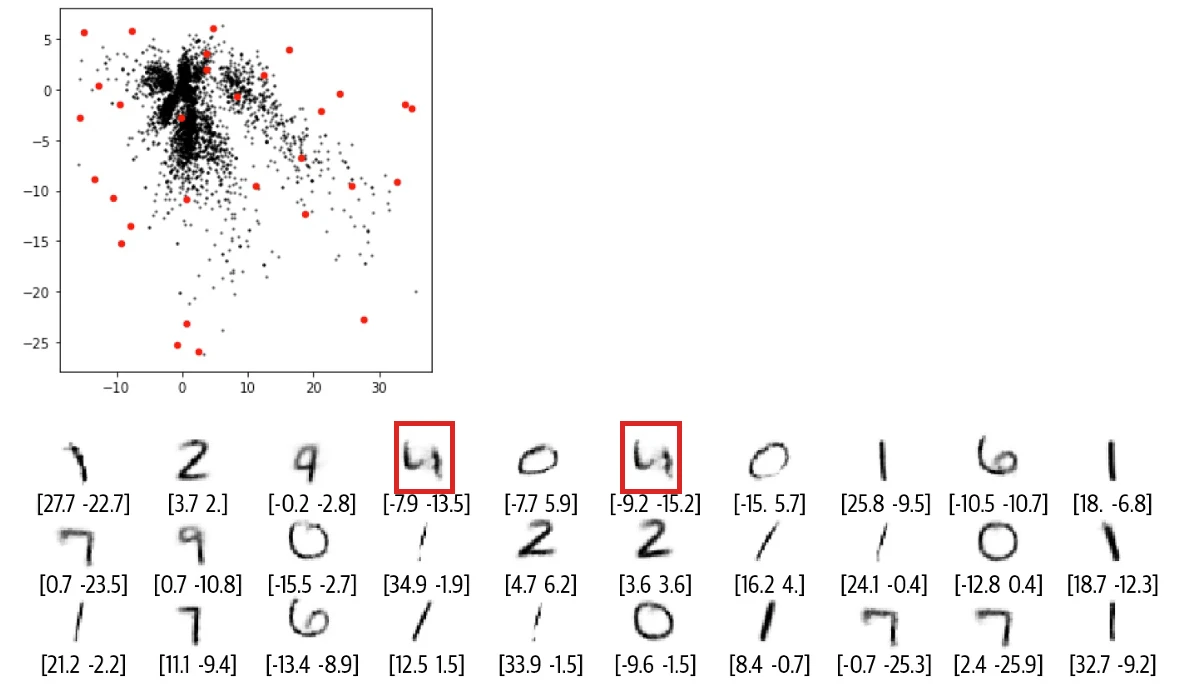
正如你所看到的,重建效果較差,有些圖甚至都分辨不出是什么數字。那么到底出了什么問題,Coder 兩兄弟該如何改進他們的方案呢?
1.自動編碼器
前言的故事其實就是類比 自動編碼器 (autoencoder),D.Coder 音譯為 encoder,即 編碼器 ,做的事情就是將圖片轉成坐標,而 N.Coder 音譯為 decoder,即 解碼器 ,做的事情就是將坐標還原成圖片。上節的兩兄弟監控的收入損失其實就是模型訓練時用的損失函數。
故事歸故事,讓我們看看自動編碼器的嚴謹描述,它本質上就是一個神經網絡,包含:
-
一個 編碼器 (encoder):用來把高維數據壓縮成低維表徵向量。
-
一個 解碼器 (decoder):用來將低維表徵向量還原成高維數據。
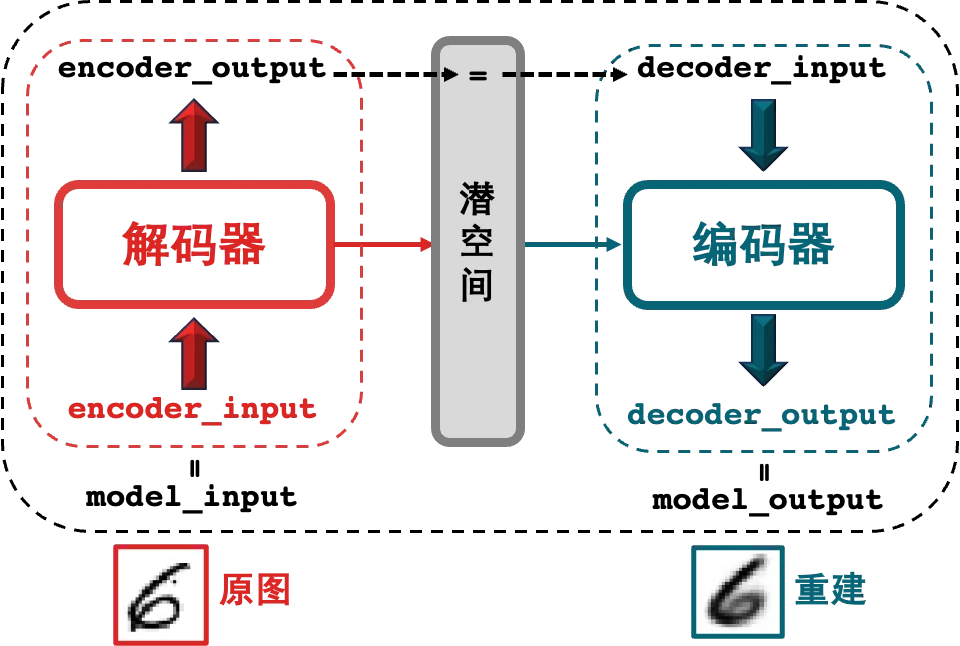
該流程如下圖所示,original input data 是高維圖片數據,圖片包含很多像素因此是高維的,而 representation vector 是低維表徵向量,本例用的二維向量 [-2.0, -0.5 ] 是低維的。
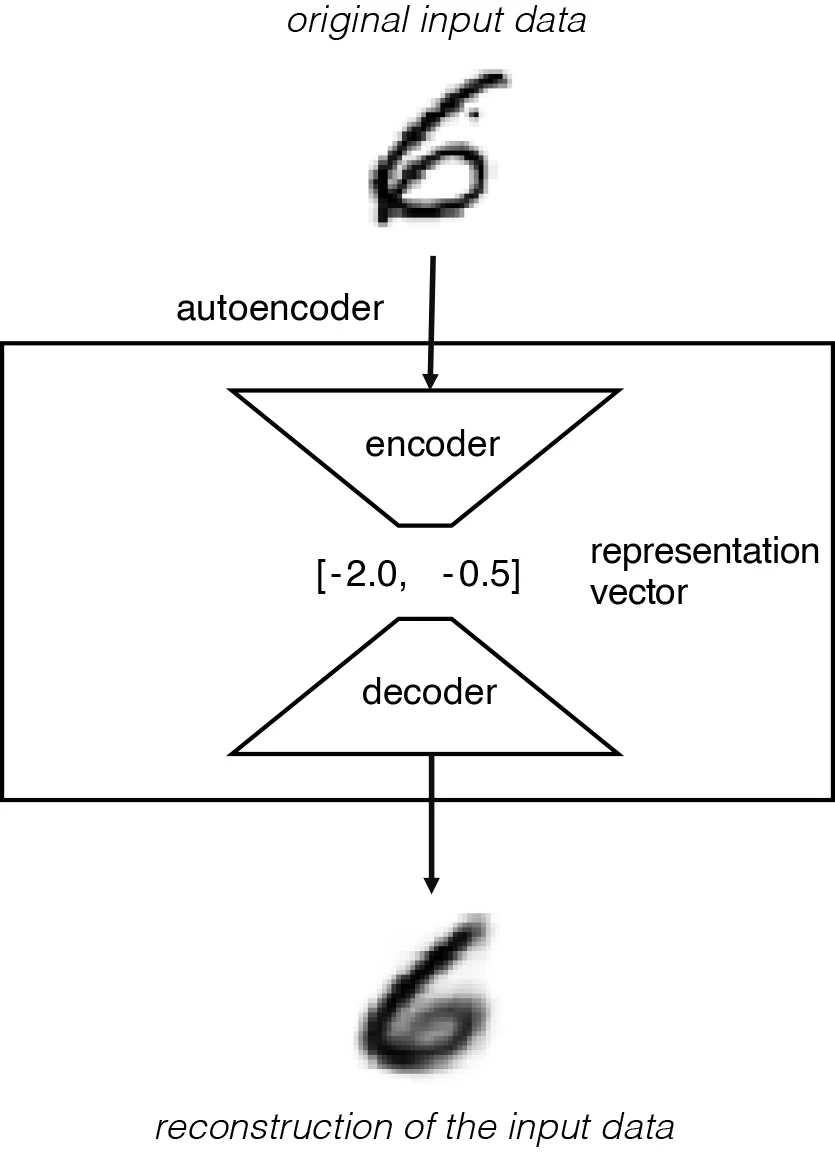
該網絡經過訓練,可以找到編碼器和解碼器的權重,最小化原始輸入與輸入通過編碼器和解碼器後的重建之間的損失。表徵向量是將原始圖像壓縮到較低維的潛空間。 通過選擇 潛空間 (latent space) 中的任何點,我們應該能夠通過將該點傳遞給解碼器來生成新的圖像,因為解碼器已經學會了如何將潛空間中的點轉換為可看的圖像。
在前言描述中,N.Coder 和 D.Coder 使用表示二維潛空間 (牆壁) 內的向量對每個圖像進行編碼。之所以用二維是為了可視化潛空間,在實踐中,潛空間通常高過兩維,以便更自由地捕獲圖像中更大的細微差別。
2.模型解析
2.1 初次見面
一般來說,最好用單獨的文件來創建模型的類,比如下面的 Autoencoder class。這樣其他項目可以靈活調用此類。下面代碼首先展示了 Autoencoder 的框架,__init__() 是構造函數,通過調用 _build() 來創建模型,compile() 函數用於設定優化器,save() 函數用於保存模型,load_weights() 函數用於下次使用模型時加載權重,train() 函數用於訓練模型。
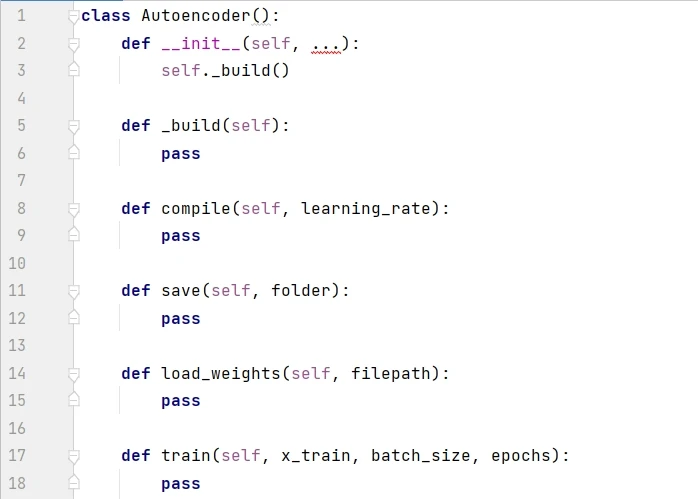
構建函數包含 8 個必需參數和 2 個默認參數,input_dim 是圖片的維度,z_dim 是潛空間的維度,剩下的 6 個必需參數分別是編碼器和解碼器的濾波器個數 (filters)、濾波器大小 (kernel_size)、步長大小 (strides)。
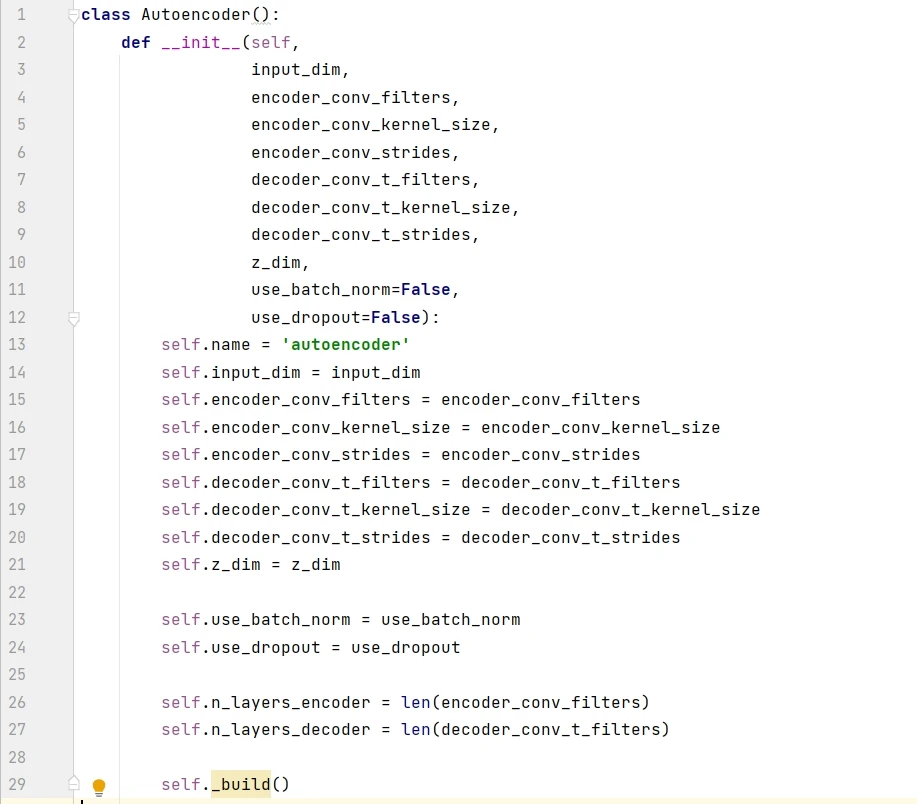
用構建函數創建自動編碼器,命名為 AE。輸入數據是黑白圖片,其維度是 ( 28, 28, 1),潛空間用的 2D 平面,因此 z_dim = 2 。此外六個參數的值都是一個大小為 4 的列表,那么編碼模型和解碼模型都含有 4 層。
在 AutoEncoder 類裏面定義 _build() 函數,構建編碼器和解碼器並將兩者相連,代碼框架如下 (後三小節會逐個分析):

接下兩小節我們來一一剖析自動編碼器中的編碼模型和解碼模型。
2.2 編碼模型
編碼器的任務是將輸入圖片轉換成潛空間的一個點,編碼模型在 _build() 函數裏面的具體實現如下:

代碼解釋如下:
-
第 2-3 行將圖片定義為 encoder 的輸入。
-
第 5-17 行按順序將卷積層堆起來。
-
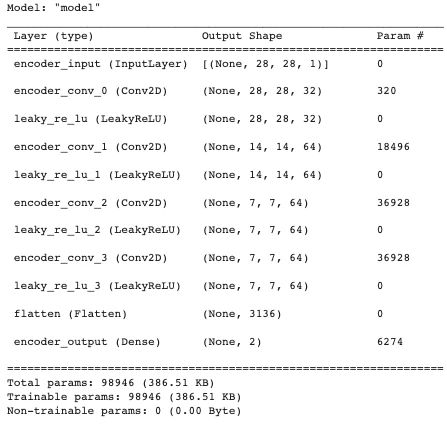
第 19 行記錄 x 的形狀,K.int_shape 的返回是一個元組 (None, 7, 7, 64),第 0 個元素是樣本大小,用 [ 1:] 返回除樣本大小的數據形狀 ( 7, 7, 64)。
-
第 20 行將最後的卷積層打平成為一個 1D 向量。
-
第 21 行的稠密層將該向量轉成另一個大小為 z_dim 的 1D 向量。
-
第 22 行構建 encoder 模型,分別在 Model() 函數確定入參 encoder_input 和 encoder_output。
用 summary() 函數打印出編碼模型的信息,用來描述每層的名稱類型 (layer (type))、輸出形狀 (Output Shape) 和參數個數 (Param #)。
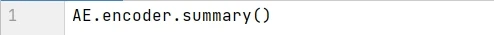
2.3 解碼模型
解碼器是編碼器的鏡像,只不過不是使用卷積層,而是使用卷積轉置層 (convolutional transpose layers) 來構建。當步長設為 2 ,卷積層每次將圖片的高和寬減半,而卷積轉置層將圖片的高和寬翻倍。具體操作見下圖。

解碼器在 _build() 函數裏面的具體實現如下:
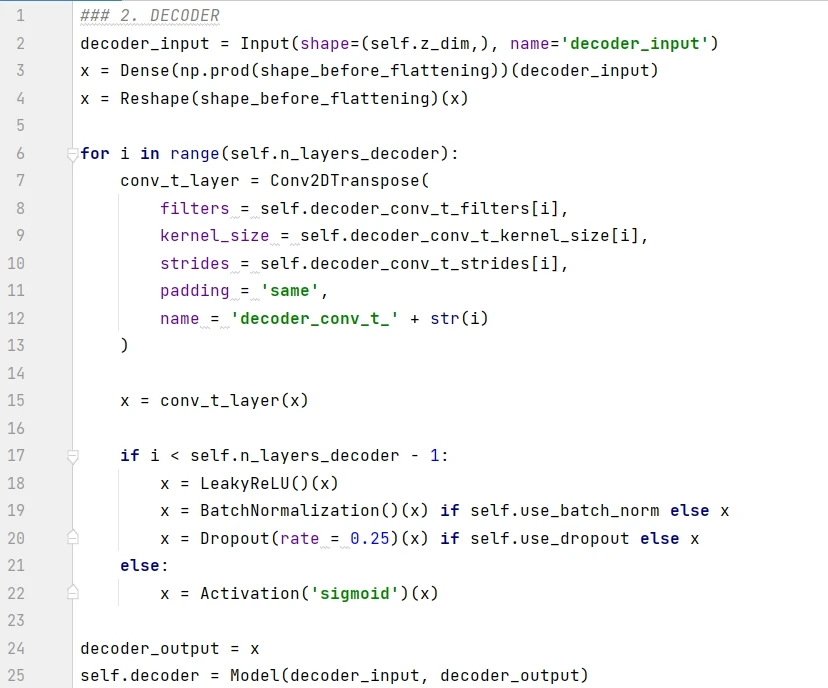
代碼解釋如下:
-
第 1 行將 encoder 的輸出定義為 decoder 的輸入。
-
第 2-3 行將 1D 向量重塑成形狀為 ( 7, 7, 64) 的張量。
-
第 6-15 行按順序將卷積轉置層堆起來。
-
第 7-22 行:
-
如果是最後一層,用 sigmoid 函數轉換,得到的結果在 0-1 之間當成像素
-
如果不是最後一層,用 leaky relu 函數轉換,並加上批歸一化 (batch normalization) 和隨機失活 (dropout) 的處理。
-
第 24-25 行構建 decoder 模型,分別在 Model() 函數確定入參 decoder_input 和 decoder_output,前者是 encoder 的輸出,即潛空間的點,而後者是重建的圖片。
用 summary() 函數打印出解碼模型的信息。


2.4 串連起來
為了能同時訓練編碼器和解碼器,我們需要將兩者連在一起,

代碼解釋如下:
-
第 1 行將 encoder_input 作為整體模型的輸入 model_input (中間產物 encoder_output 是編碼器的輸出)。
-
第 2 行將解碼器的輸出作為整體模型的輸出 model_output (解碼器的輸入就是編碼器的輸出)。
-
第 3 行構建 autoencoder 模型,分別在 Model() 函數確定入參 model_input 和 model_output。
一圖勝千言。
2.5 訓練模型
構建好模型之後,只需要定義損失函數和編譯優化器。損失函數通常選擇均方誤差 (RMSE)。編譯 complie() 函數的實現如下,用的是 Adam 優化器,學習率設為 0.0005 :


訓練模型用 fit() 函數,批大小設為 32 ,epoch 設為 200 ,代碼如下:


在測試集上隨機選 10 個看看效果:
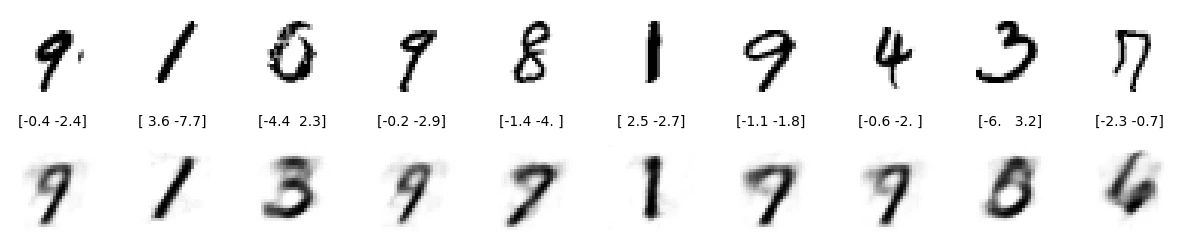
10 張圖中只有 4 張重建效果還行。
3.三大缺陷
模型訓練之後,我們可以可視化圖片在潛空間的情況。通過模型中的 encoder 在測試集生成坐標在 2D 散點圖中顯示。
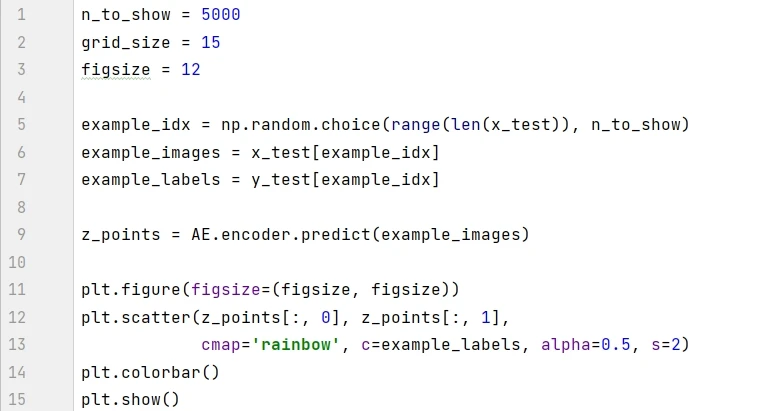
圖中有三個現象值得注意:
-
有些數字的佔地區域很小,比如紅色的 9 ,有些數字的佔地區域很大,比如紫色的 0 。
-
圖中的點對於 ( 0, 0) 不對稱,比如 x 軸上負值的點比正值的點會多很多,有些點甚至到了 x =-15 處。
-
顏色之間有很大的間隙,其中包含很少的點,如上圖左上角。
上述三大缺陷使我們從潛空間中採樣非常困難:
-
對於缺陷 1 , 由於數字 9 比 0 的佔地區域大,那么我們更容易採樣到 9 。
-
對於缺陷 2 ,從技術上講,我們可以採樣平面上任何點。但每個數字的分布是不確定的,如果分布不是對稱的話,那么隨機採樣的會很難操作。
-
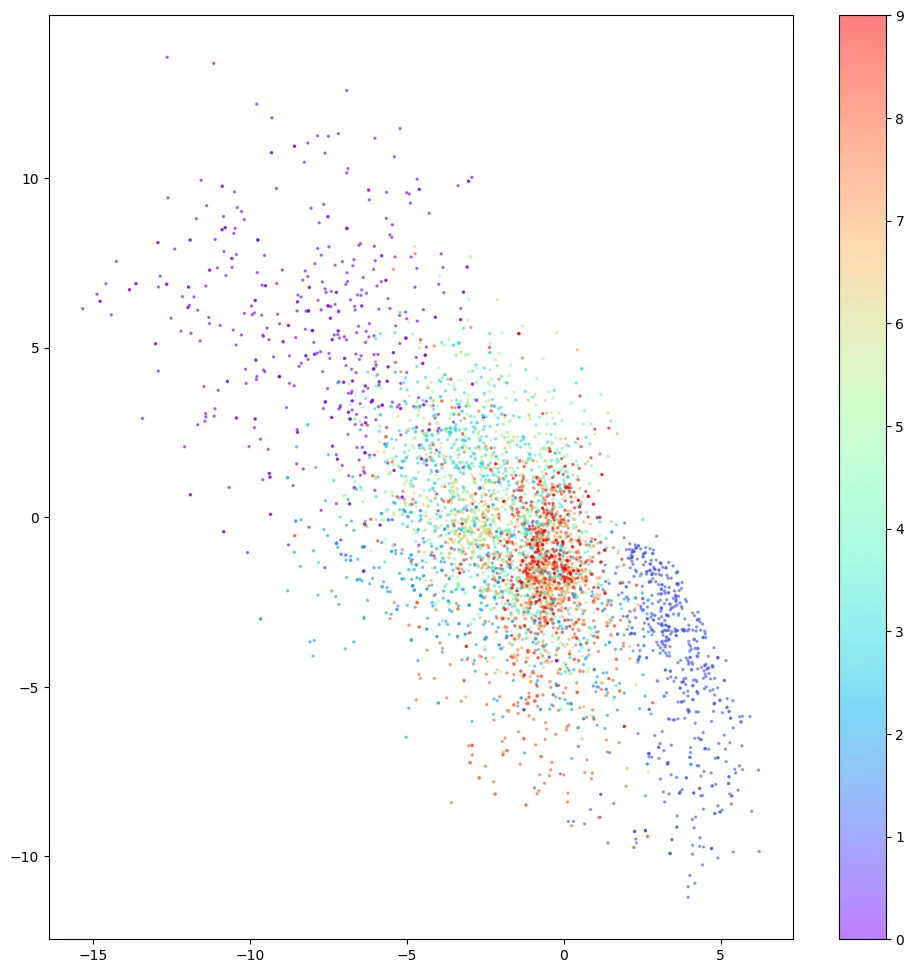
對於缺陷 3 ,從下圖可看出從潛空間中的空白處有的根本重構不出像樣的數字。
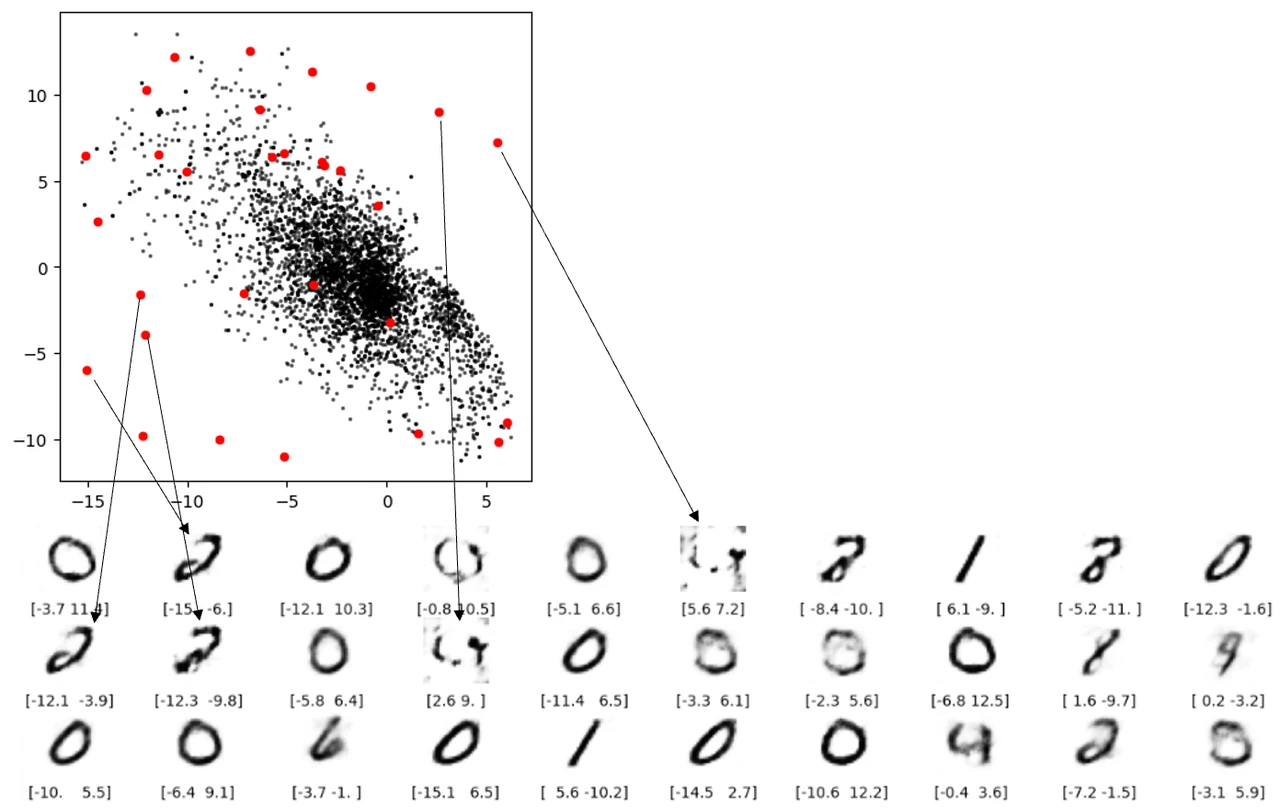
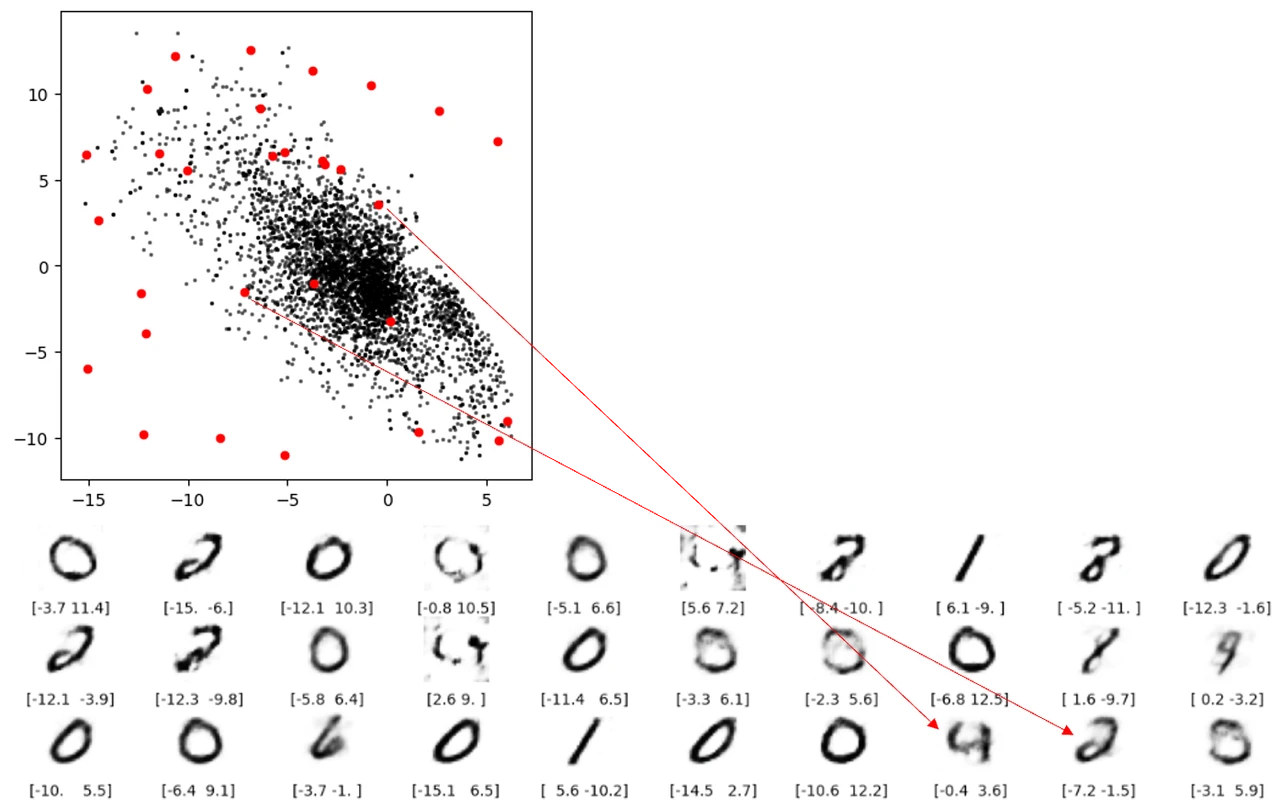
缺陷 3 空白出重構不出數字還好理解,但下圖兩條紅线表示的重構就讓人擔憂了。這兩個點都不在空白處,但是還是無法解碼成像樣的數字。根本原因就是自動編碼器並沒有強制確保生成的潛空間是連續的,例如,即便 ( 2,-2) 能夠生成令人滿意的數字 4 ,但該模型沒有一個機制來確保點 ( 2.1, – 2.1) 也能產生令人滿意的數字 4 。
總結
自動編碼器只需要特徵不需要標籤,是一種無監督學習的模型,用於重建數據。該模型是一個生成模型,但從上節提到的三大缺陷,該生成模型對於低維黑白數字的效果都不好,那么對於高維彩色人臉的效果會更差。
這個自編碼器框架是好的,那么我們應該如何解決這三個缺陷能生成一個強大的自動編碼器。這個就是下篇的內容, 變分自動編碼器 ( V ariational A uto E ncoder, VAE )。

鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
Uniswap公告Unichain主網明年初上線!首測路線圖兩功能,UNI強彈17%
去 中心化交易所(DEX)龍頭 Uniswap 於 10 月宣佈推出專為 DeFi 設計的 Lay...
下周必關注|LayerZero決定是否开啓“費用开關”;Aligned空投注冊結束(12.23-12.29)
下周重點預告 12 月 23 日 Aligned 將向 891322 個地址空投 26% 的 AL...
空投周報 | OpenSea基金會官推上线;Azuki、Doodles疑似即將發幣(12.16-12.22)
@OdailyChina @web3_golem Odaily星球日報盤點了 12 月 16 日至...
資金費率的演變:從2021年黃金時代,到2024-2025年套利復興
資金費率起源 資金費率起源於加密貨幣衍生品市場,特別是從永續期貨合約中發展而來。它作為一種機制,用...
星球日報
文章數量
7670粉絲數
0