以太坊多鏈發展前路何方,或許波卡能給參考答案
原文:《Shared sequencers for Starknet and Madara app chains》
作者: Apoorv Sadana
編譯:Odaily星球日報夫如何

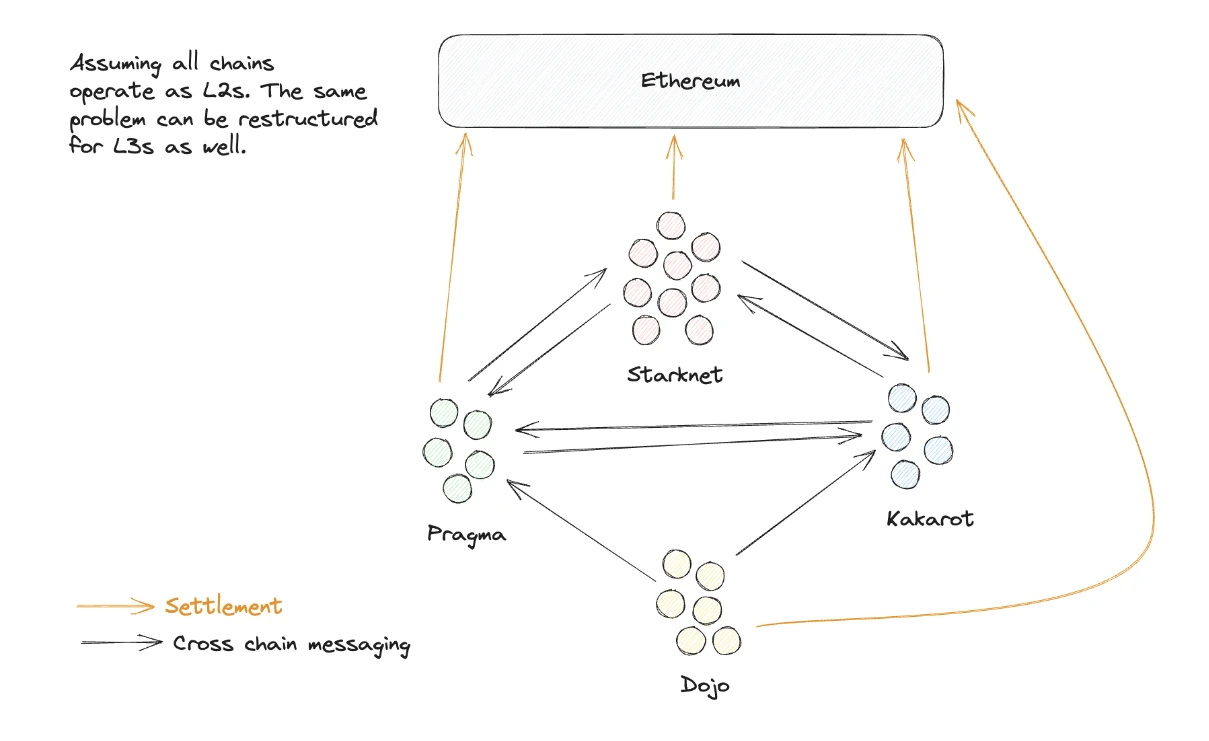
當越來越多的L2、應用鏈依靠以太坊作為結算層後,多鏈之間的互操作性和每條鏈的去中心化程度就顯得尤為重要。
本文討論了共享排序器的概念,共享排序器可以使不同的應用鏈共享一組驗證者來實現去中心化,並通過訂單引擎和 Rollup 引擎來處理交易排序和執行。
但共享排序器和 Polkadot 的多鏈設計架構具備高度相似性,可否將 Polkadot 現成的技術引入以太坊生態系統,從而提高以太坊多鏈的發展進程。
以下由Odaily星球日報編譯。
100 個應用鏈會發生什么?
假設我們處在一個未來,現在有 100 個不同的應用鏈在以太坊上結算。讓我們來解決這將引發的問題。
去中心化的碎片化
每個應用鏈都需要自行解決去中心化的問題。現在,應用鏈的去中心化並不像L1那樣必要,主要是因為我們依賴L1來確保安全性。然而,我們仍然需要去中心化來確保生命力、抵抗審查和避免壟斷優勢(例如高費用)。然而,如果每個應用鏈都採用自己的方式解決去中心化問題,這將導致驗證者集的碎片化。每個應用鏈都必須开發經濟激勵措施來吸引新的驗證者。此外,驗證者還需要選擇他們愿意運行的客戶端。這為开發者啓動自己的應用鏈創造了巨大的准入門檻(與部署智能合約相比,後者只是一次交易)。
可組合性
可組合性基本上意味着跨應用的交互。在以太坊或 Starknet 上,這僅僅意味着調用另一個智能合約,其他一切都由協議自己處理。然而,在應用鏈中,這變得更加困難。不同的應用鏈有自己的區塊和共識機制。每次嘗試與另一個應用鏈交互時,你需要仔細審查共識算法和最終性保證,並相應地設置跨鏈橋接(直接到鏈上或通過L1)。如果你想與 10 個具有不同設計的應用鏈交互,你需要做這 10 次。
开發體驗
解決去中心化和橋接並不容易。如果每個應用鏈都需要解決這些問題,對於普通的智能合約开發者來說,建立自己的應用鏈將變得非常困難。此外,由於每個應用鏈都試圖以自己的方式解決這些問題,我們很快會看到不同的鏈遵循不同的標准,這將使新項目方加入生態系統變得更加困難。
共享排序器可以解決這個問題
如果你關注應用鏈領域,你可能聽說過“共享排序器”這個術語。它是指為解決上述問題而共享一組公共驗證者的想法。它的工作原理如下。
共享去中心化
共享排序器的核心思想是不需要為每個應用鏈或L2擁有不同的驗證者集。但可以擁有一組非常高效和去中心化的驗證者,為所有的鏈排序區塊。
由於今天幾乎每個排序器都是集中化的,排序器被視為一個單一應用程序,它收集交易,對它們進行排序,執行它們,並將結果發布到L1上。然而,這些任務可以分解為多個模塊化組件。出於解釋的需要,我將其分為兩個部分。
排序引擎: 負責按照特定的順序對交易進行排序。一旦排序引擎決定了這個順序,就必須遵循此順序。此舉在L1上提交此順序並強制L1驗證者檢查是否按照所需的順序執行交易來實施的。
Rollup 引擎: Rollup 引擎基本上包括 Rollup 所做的一切:從用戶收集交易,執行交易,創建證明並更新L1上的狀態。理想情況下,這可以分解為更多的組件,但在本文中我們將避免這樣做。 在這裏,排序引擎是共享排序器,Rollup 引擎基本上是所有 Rollup 邏輯。
因此,交易的生命周期如下所示。
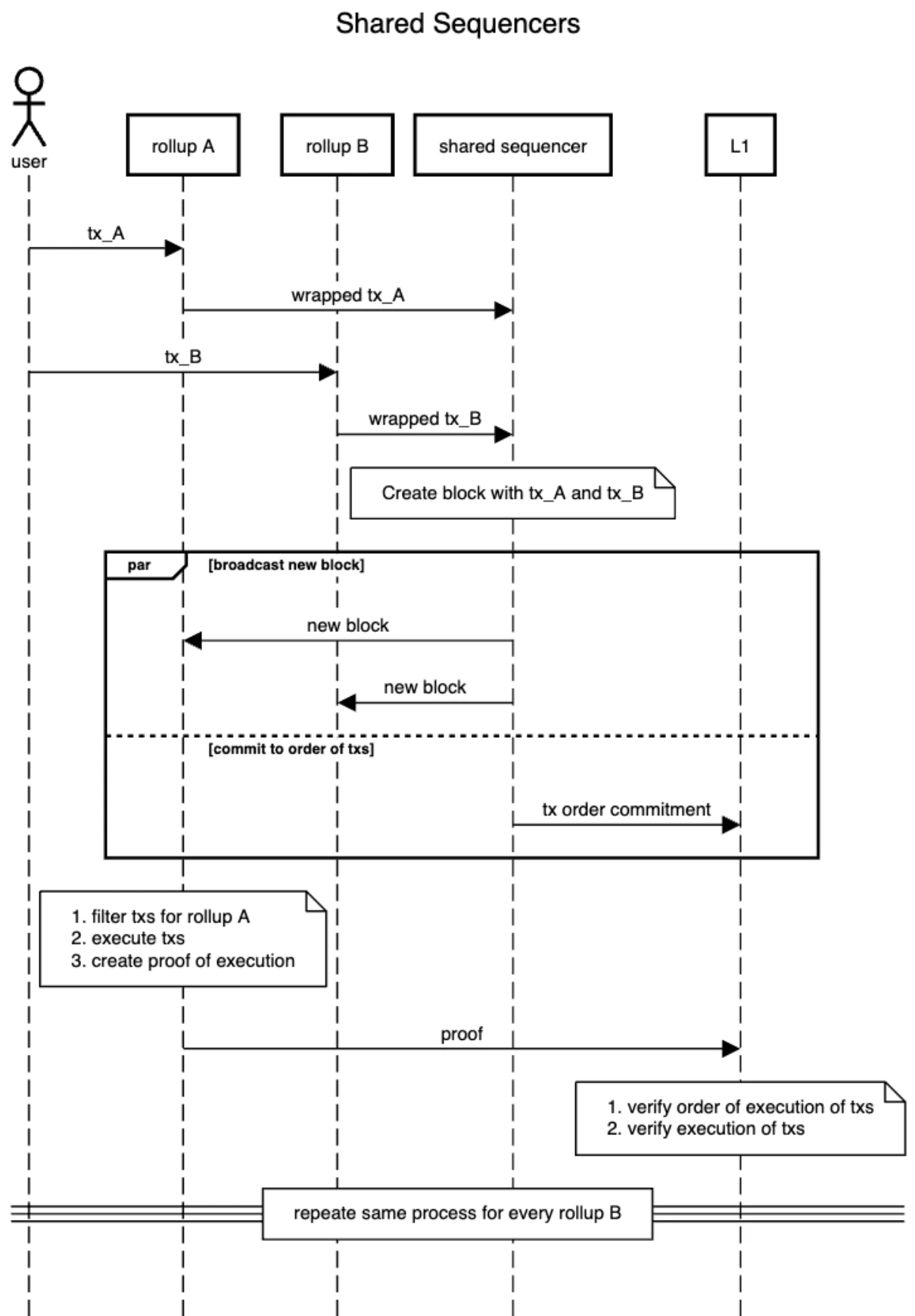
共享排序器基本上對 Rollup 中的交易進行排序,並將其提交到L1上。共享排序器通過將共享排序器集合去中心化,也就意味着與該排序器集合連接的所有 Rollup 都變得去中心化了。
可組合性
可組合性的一個主要問題是了解交易在其他應用鏈上何時最終完成,並相應地在鏈上採取行動。但是共享排序器可以讓可組合的 Rollup 互相共享區塊。因此,如果在 Rollup B 上發生交易回滾,整個區塊都會回滾,這也導致 Rollup A 上的交易回滾。
現在,這聽起來肯定比實際操作要容易。為此,Rollup 之間的通信需要高效且可擴展。共享排序器需要制定關於 Rollup 如何通信、跨鏈消息應該是什么樣子、如何處理 Rollup 升級等方面的適當標准。盡管這些問題是可以解決的,但也不易實現。
开發者體驗
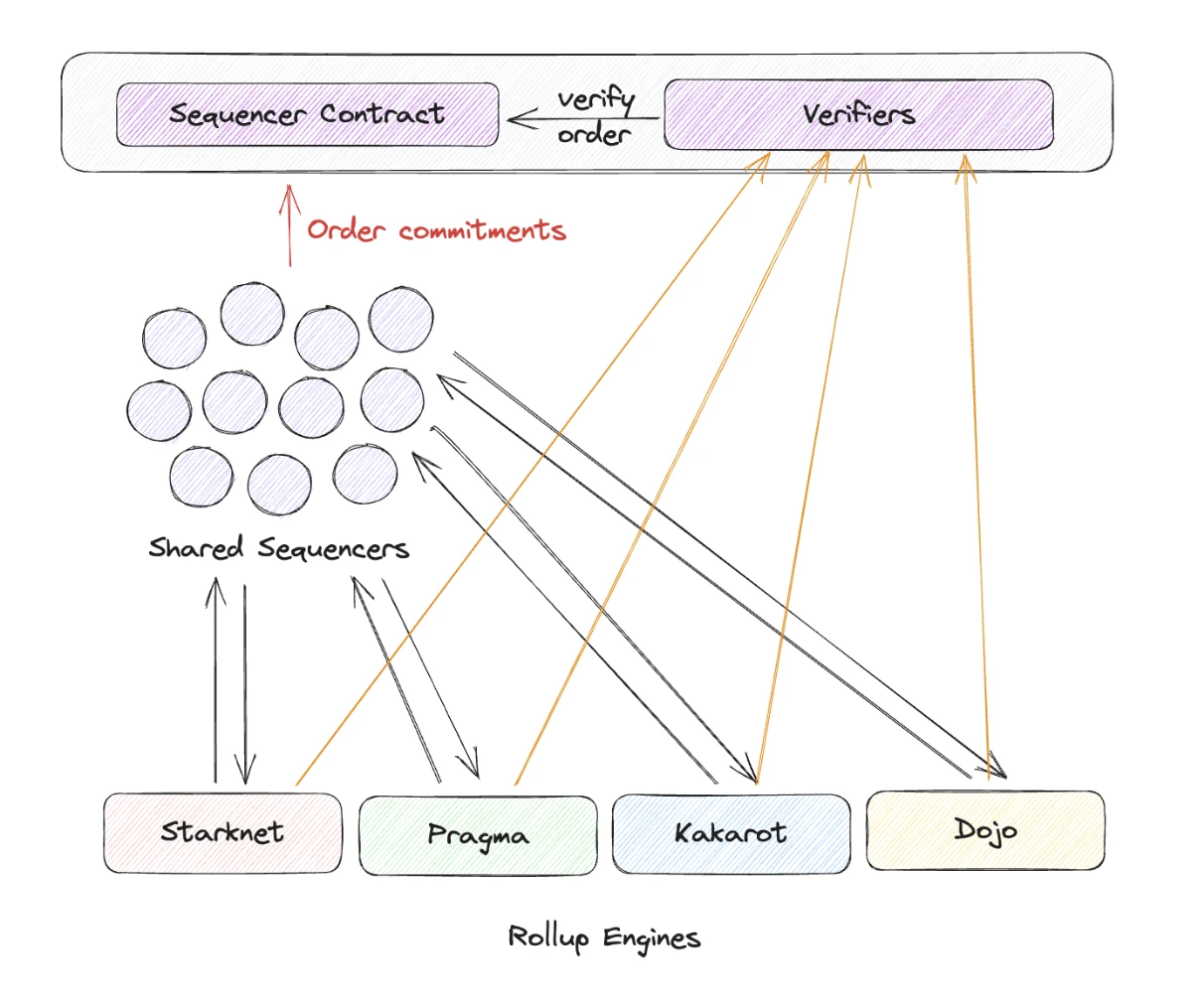
雖然共享排序器確實抽象了去中心化方面,使跨鏈消息傳遞變得更容易,但每個鏈仍然需要遵循一些標准,以與共享排序器兼容。例如,所有 Rollup 交易都需要轉換為排序器所理解的通用格式。同樣,需要過濾排序器的區塊以獲取相關交易。為了解決這個問題, 我認為共享排序器將推出 Rollup 框架或 SDK,將樣板代碼抽象出來,只向應用鏈开發者公开業務邏輯部分。
以下是應用鏈在使用共享排序器時的示意圖。
以太坊多鏈可否借鑑 Polkadot 的設計架構
Polkadot 在以太坊之前就开始着手多鏈的未來。實際上,他們已經在這方面工作了 5 年多了。如果你熟悉 Polkadot,你可能已經注意到上面的設計基本上是重新發明了 Polkadot 已經完成的許多事情。
中繼鏈(共享去中心化)
中繼鏈基本上就是上面序列圖中的排序引擎+L1。中繼鏈的功能包括:
對所有平行鏈(Rollup)的交易進行排序 驗證交易是否正確執行(它不使用零知識驗證,而是重新運行 Rollup 的執行代碼,以驗證狀態差異)。
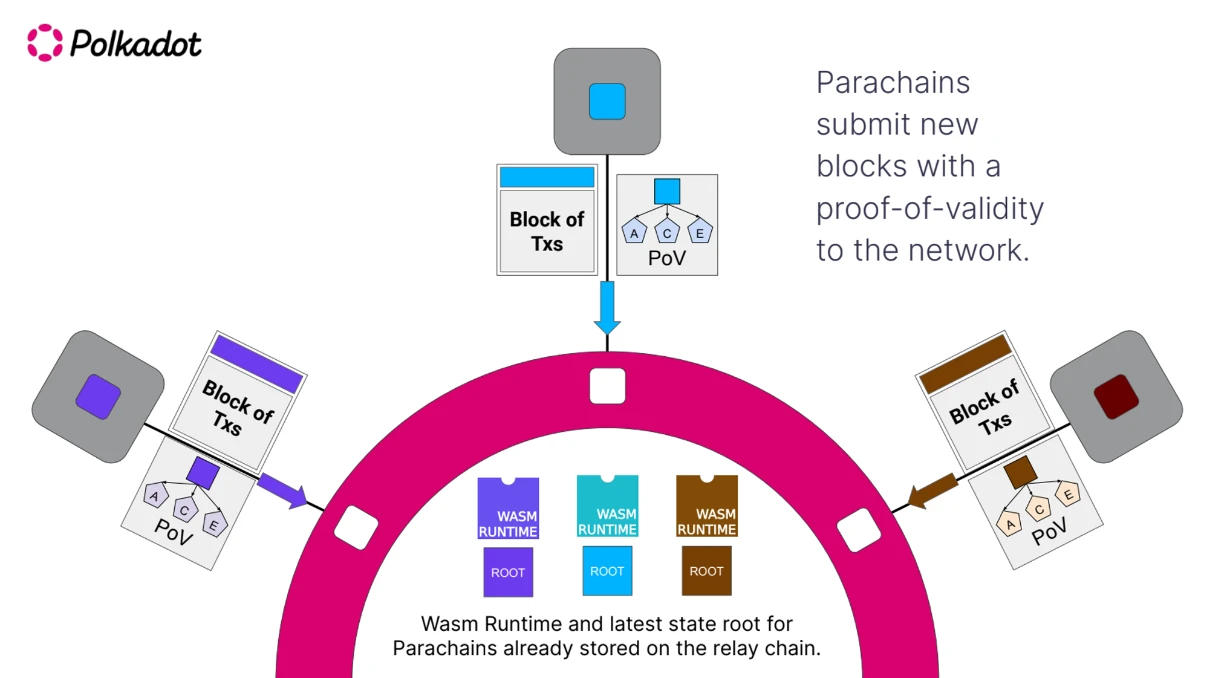
你可能已經意識到,中繼鏈基本上就是我們上面討論過的共享排序器。不同的是,中繼鏈還需要驗證執行,而我們將這一點留給了以太坊。
XCM 和 XCMP
我們在前面的部分提到,如果每個鏈都建立自己的方法來與其他鏈進行互操作,那么很快我們就會在所有鏈上看到不同的標准和格式。你需要跟蹤與每個鏈交互的所有這些格式。此外,你還需要回答諸如如果一個鏈升級會發生什么之類的問題。然而,這些問題可以通過引入所有鏈必須遵循的標准來解決。
正如你可能已經猜到的,Polkadot 已經做到了這一點。XCM 是消息格式,XCMP 是消息協議,所有的子鏈都可以使用它們來相互通信。
Substrate 和 Cumulus
Substrate 是 Parity 开發的一個用於構建區塊鏈的框架。雖然 Polkadot 上的所有平行鏈都使用 Substrate,但 Substrate 實際上是以鏈無關的方式構建的。該框架抽象了區塊鏈的所有通用方面,專注於應用邏輯。正如我們所知,Madara 是基於 Substrate 構建的,Polkadot、 Polygon Avail 和許多其他項目也是如此。此外,Cumulus 是在 Substrate 之上的中間件,可以將你的鏈連接到 Polkadot。
因此,繼續之前的類比,Substrate 和 Cumulus 可以被視為替代 Rollup 框架的解決方案,它們允許構建應用鏈並將其連接到共享排序器。
共享排序器 → 中繼鏈
可組合性 → XCM 和 XCMP
Rollup 框架/堆棧 → Substrate 和 Cumulus

上述基本上就是 Polkadot 的翻版,除此之外,Polkadot 和 Parity 擁有一些經驗豐富且資金充裕的團隊,他們繼續改進 Substrate 和 Polkadot,增加更多功能並提高可擴展性。這項技術經過多年的實战測試,並且具備豐富的开發工具。
在以太坊上結算 Polkadot?
雖然 Polkadot 確實在以太坊之前开始構建多鏈的未來,但無可否認的是,截至今天,以太坊是最具去中心化的區塊鏈,也是大多數應用和流動性所在的地方。然而,如果有一種方法將所有 Polkadot 技術引入以太坊生態系統,會怎樣呢?
實際上,我們已經开始這個工作了,Madara 就是一個例子。Madara 使用 Substrate 框架允許任何人在以太坊上構建自己的基於 zk 的L2/L3解決方案。接下來我們需要的是以共享排序器形式的 Polkadot 中繼鏈。如果我們可以重用 Polkadot 中繼鏈,但是移除驗證部分,因為在L1上通過 zk 證明進行驗證 將交易的順序提交到L1上 優化節點和共識算法,以支持 Tendermint /HotStuff 我們就可以得到前面提到的共享排序器。
顯然,這說起來容易做起來難。然而,我認為這條道路比從頭开始重建排序器、標准和框架更加務實。Polkadot 已經以一種與鏈無關的方式解決了許多問題,我們可以借鑑它們用於以太坊。作為一個附帶產品,我們也能得到:
● 一個積極开發者社區,繼續為 Substrate 構建和教育全世界。
● 一個活躍的开發工具集和強大的社區。
● 許多活躍的平行鏈也可以選擇在以太坊上結算,如果他們愿意這樣做的話(最近我們看到 Astar 使用 Polygon CDK 做了同樣的事情) 。
結論
我撰寫這篇文章的主要目的是在 Starknet 和以太坊的更廣泛生態系統中引發討論。我認為共享排序模型將在 Starknet 的去中心化以及所有考慮在其上構建的應用鏈的去中心化中起着重要的作用。只要我們對應用鏈的論點和 zk 擴展性有信心,對共享排序模型進行徹底的分析是不可避免的。 此外,隨着 Madara 向生產環境邁進,Starknet 已經开始了去中心化的工作,我認為現在是解決這個問題的時候了。因此,我請求每個閱讀這篇文章的人對這個話題提出任何反饋/建議。期待閱讀你的想法。
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
Uniswap公告Unichain主網明年初上線!首測路線圖兩功能,UNI強彈17%
去 中心化交易所(DEX)龍頭 Uniswap 於 10 月宣佈推出專為 DeFi 設計的 Lay...
下周必關注|LayerZero決定是否开啓“費用开關”;Aligned空投注冊結束(12.23-12.29)
下周重點預告 12 月 23 日 Aligned 將向 891322 個地址空投 26% 的 AL...
空投周報 | OpenSea基金會官推上线;Azuki、Doodles疑似即將發幣(12.16-12.22)
@OdailyChina @web3_golem Odaily星球日報盤點了 12 月 16 日至...
資金費率的演變:從2021年黃金時代,到2024-2025年套利復興
資金費率起源 資金費率起源於加密貨幣衍生品市場,特別是從永續期貨合約中發展而來。它作為一種機制,用...
星球日報
文章數量
7670粉絲數
0