A16Z:面对天价算力,AI开发者如何突破困境?
原文由Guido Appenzeller, Matt Bornstein, and Martin Casado撰写
EMC爱好者编译整理
天价模型:高成本与高时间
-
底层的算法问题在计算上非常复杂且困难,因而AI的基础设施本身就很昂贵。
-
不过对于Transformer来说,人们可以估计特定大小的模型将消耗多少计算和内存。因此,选择合适的硬件成为下一个考虑因素。
-
按照传统CPU的速度,在不利用任何并行架构的情况下,执行单个 GPT-3 的推理操作将需要花费 32 小时。这种速度显然是不行的。
-
生成式 AI 需要对现有的 AI 基础设施进行大量投资。训练像 GPT-3 这样的模型,是人类有史以来计算量最大的任务之一。虽然GPU越来越快,开发者们也找到了优化训练的方法,但AI的快速扩张抵消了这两种影响。
AI基础设施:自己建造还是花钱买?
内部自建&外部设施
-
像OpenAI、Hugging Face、和Replica这样的托管模型服务,允许创始人快速搜索产品与市场的契合度,无需管理底层基础设施或模型。
-
这些服务的定价是基于消费的,因此它通常也比单独搭建运行的基础设施便宜。
-
另一方面,训练新基础模型或构建垂直集成的AI初创公司,无法避免直接在GPU上运行自己的模型。因为模型实际上是产品,团队正在寻找“模型-市场契合度”;控制训练和推理才能实现某些功/或大规模降低边际成本。无论哪种方式,管理基础架构都可以成为竞争优势的来源。
云VS数据中心
-
大多数情况下,云是最适合构建AI基础设施的地方。
-
例外情况:
(1)运营规模非常大的情况下,运行自己的数据中心可能更划算。每个地方或许价格不一,但开支通常> 5000 万美元/年。
(2)云提供商无法提供您需要的特定硬件,例如未广泛使用的 GPU 类型,以及异常的内存、存储或网络要求。
如何选择云服务提供商?
-
价格:特定硬件上的算力是一种商品。虽然我们期望价格统一,但事实并非如此。在价格规模的顶端,大型公共云根据品牌声誉、经过验证的可靠性以及管理各种工作负载的需求收取溢价。较小的专业AI提供商能提供较低的价格,要么通过运行专用数据中心(例如Coreweave)或套利其他云(例如Lambda Labs)。
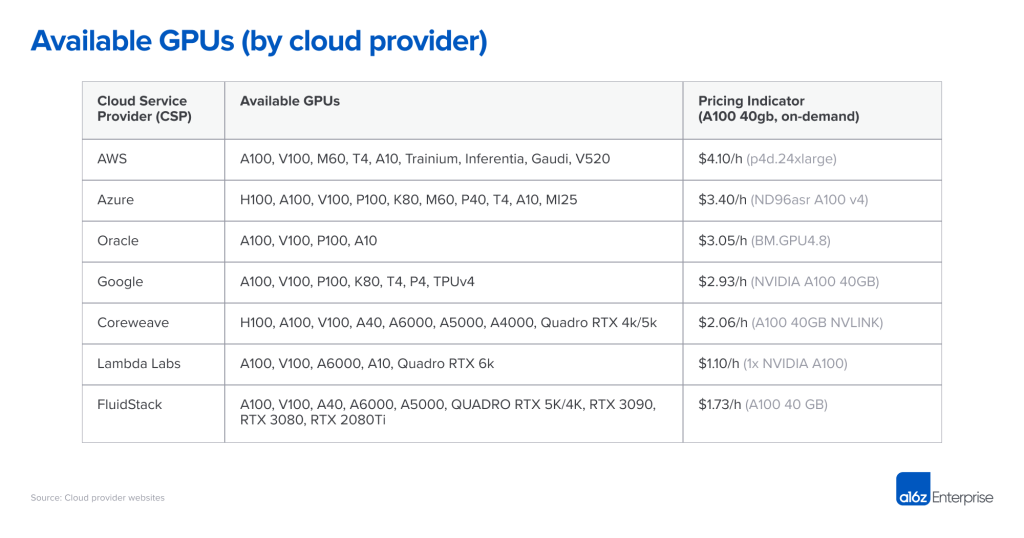
-
可用性:人们普遍认为前三大云服务供应商可用性最前,不过许多初创企业发现事实未必如此。大型云有很多硬件,但也需要满足大量的客户需求, 例如Azure是ChatGPT的主要主机,并且不断增加/租赁容量以满足需求。与此同时,英伟达致力于在整个行业中广泛提供硬件,包括为新的专业提供商分配硬件。
-
计算交付模型:由于尚未解决GPU虚拟化的问题,今天的大型云仅提供具有专用GPU的实例。专用 AI 云提供其他模型,例如容器或批处理作业,这些模型可以处理单个任务,而不会产生实例的启动和拆卸成本。如果您对这种模型感到满意,它可以大大降低成本。
-
网络互连:对于模型训练而言,选择提供商时主要考虑网络带宽。需要节点之间具有专用结构的集群(例如 NVLink)来训练某些大型模型。对于图像生成AI而言,出口流量费用也可能是一个主要的成本驱动因素。
如何选择GPU?
-
训练与推理:训练大型模型是在机器集群上完成的,每台服务器最好有许多 GPU、大量 VRAM 以及服务器之间的高带宽连接。许多型号在 NVIDIA H100 上最具成本效益,但截至今天很难找到,而且通常需要一年以上的长期投入。而今NVIDIA A100 可以运行大多数模型训练,也容易接触到,但对于大型集群,可能还需要长期投入。
-
内存要求:大语言模型的参数计数太高,往往需要H100或A100,但是较小模型(例如稳定扩散)所需要的VRAM要少得多。虽然A100仍然很受欢迎,不过许多初创公司已开始使用A10,A40,A4000,A5000和A6000,甚至RTX卡。
-
硬件支持:目前A16Z的调研结果里,绝大多数工作负载都在 NVIDIA 上运行,但少数公司已经开始尝试其他供应商,例如谷歌TPU以及英特尔的Gaudi2,模型性能通常高度依赖于这些芯片的软件优化可用性。
-
延迟网络要求:通常,延迟敏感度较低的工作负载(例如,批处理数据处理)可以使用功能较弱的 GPU,将计算成本降低多达 3-4 倍。另一方面,面向用户的应用程序通常需要高端卡来提供实时用户体验。优化模型通常是必要的,以使成本达到可管理的范围。
模型优化策略
-
适用于广泛模型的策略:
(1)使用较短的浮点表示(即 FP16 或 FP8 与原始 FP32)或量化(INT8、INT4、INT2)可实现加速,通常与比特的减少呈线性关系。
(2)修剪神经网络,通过忽略低值的权重来减少权重的数量。
(3)另一组优化技术解决了内存带宽瓶颈(例如,通过流式模型权重)。
-
针对于特定模型的策略:Stable Diffusion在推理所需的VRAM量方面取得了重大进展。
-
针对于特定硬件的优化:NVIDIA的TensorRT包括许多优化,但仅适用于NVIDIA硬件。
-
调度AI任务的调度可能会带来性能瓶颈,也可能带来提升。将模型分配给 GPU 以最大程度地减少权重交换,为任务选择最佳 GPU(如果有多个 GPU)以及通过提前批处理工作负载,可最大程度地减少停机时间。
成本如何演变?
-
过去几年间,模型参数和 GPU 计算能力呈指数级增长。
-
人们普遍认为,最优参数数量与训练数据集的大小之间存在关系。今天最好的大语言模型是在Common Crawl(45亿个网页的集合)上进行训练的。
-
转录视频或音频内容等想法也横空出世,但尚未形成规模。目前尚不清楚我们是否可以获得比已经使用的数据集大 10 倍的非合成训练数据集。
-
GPU 性能将继续提高,但速度也会放缓。摩尔定律仍然完好无损,允许更多的晶体管和更多的内核,但功率和I输入/ 输出正在成为限制因素。
-
算力需求仍会增加。即使模型和训练集的增长放缓,人工智能行业的增长和人工智能开发人员数量的增加也将推动对更多、更快的GPU的需求。
-
LLM的培训成本在今天可能看起来像一条护城河,不过Alpaca以及Stable Diffusion这样的开源模型已经表明,这些市场还处于早期阶段,可能会迅速变化。
郑重声明:本文版权归原作者所有,转载文章仅为传播信息之目的,不构成任何投资建议,如有侵权行为,请第一时间联络我们修改或删除,多谢。
早报 | Lighter 24 小时交易量突破 110 亿美元;Circle Q3 财报公布;Strategy 美股市值跌破其 BTC 持仓价值
整理:ChainCatcher 重要资讯: 币安将停止币安直播平台服务,币安广场将继续提供直播服务...
24H热门币种与要闻 | Sui将推出原生稳定币USDsui;美SEC拟推出基于Howey测试的代币分类法(11月13日)
1、CEX 热门币种 CEX 成交额 Top 10 及 24 小时涨跌幅: BNB -0.78%...
博链财经
文章数量
738粉丝数
0