解讀ZKEVM:編譯Solidity源碼到LLVM IR系列(一)
零知識證明(ZKP)發展至今,大多數方案都是基於低級別表述語言實現的,例如 QAP、R1CS 或 Circuit。盡管 ZKP 不受語言限制,可以使用任何語言定義,但是高級語言所帶來的生成證明的復雜度卻是難以接受的。因此很多區塊鏈技術團隊开始使用新的 DSL 語言去編寫業務邏輯,來實現復雜度較低的證明,但是這種模式卻增加了用戶編寫合約的難度,因為大多數用戶根本沒有時間和精力學習 Rust、C++ 等語言。
Matter Labs 團隊為了解決 ZKP 的圖靈完備問題,引入了 ZINC 這門新的編寫智能合約的語言。 然而該團隊在 Youtube 上一段 ZKEVM 設計視頻中曾公开表示 ZINC 目前並不是圖靈完備的,缺乏循環、遞歸等內容。團隊還表示,為了減少引入新的語言給开發者帶來的學習成本,將嘗試採用 Solidity-> YUL -> LLVM IR-> ZKEVM 的技術路线。
受該視頻啓發,本系列文章將與讀者探討使用 LLVM 編譯器編譯 Solidity /YUL字節碼 到 R1CS 或 Circuit 的過程。盡管該方案後續可能發生重大變化,但是也是一次很好的學習機會。
第一篇 LLVM 介紹
概念
LLVM是模塊化和可重用的編譯器與工具鏈技術的集合, 經常被誤認為是一個單純的編譯器,拿來跟 Clang 和 GCC 進行比較,實際上 Clang 也是僅僅作為 LLVM 項目的一部分單獨發行的。以下是對這幾個概念的詳細介紹。
LLVM:LLVM 和虛擬機技術沒有關系。它的名字並不是一個縮寫,而是 LLVM 項目的全稱。LLVM 的目標是提供一個現代化的、基於 SSA 編譯策略的、同時支持靜態和動態編譯任何編程語言的編譯器架構。現在 LLVM 已經發展成為一個由多個子項目組成的總體項目,其中許多子項目已被廣泛應用於學術研究、商業和开源項目中。LLVM 核心庫提供了與編譯器相關的支持,可以作為多種語言編譯器的後端來使用。能夠進行程序語言的編譯期優化、鏈接優化、在线編譯優化和代碼生成。
Clang:是 LLVM 的一個編譯器前端,它目前支持 C, C++, Objective-C 以及 Objective-C++ 等編程語言。Clang 對源程序進行詞法分析和語義分析,並將分析結果轉換為 Abstract Syntax Tree(AST 抽象語法樹) 和LLVM-IR,最後使用 LLVM 作為後端代碼的生成器。
GCC:GNU編譯器套件(GNU Compiler Collection)包括C、C++、Objective-C、Java、Go語言的前端,也包括這些語言的庫(如 libstdc++、libgcj 等)。GCC的开發初衷便是一款專為GNU操作系統設計的編譯器。
傳統編譯器的三段式設計
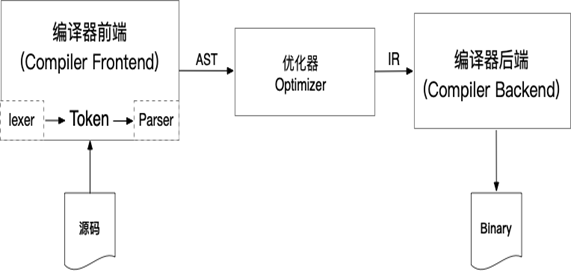
傳統的靜態編譯器(例如大多數C編譯器)採用三段式設計:前端、優化組件和後端。前端組件解析程序源代碼,檢查語法錯誤,生成一個基於語言特性的 AST(Abstract Syntax Tree)來表示輸入代碼,並提供給優化器。優化器會對AST數據進行相應的優化處理,以便最大程度的提升源代碼的執行效率。優化後的中間表示代碼(IR)會被送往後端程序。後端編譯器會進行指令選擇、寄存器分配等操作,最後將IR轉化為相應平臺的機器碼。
優化器的作用是採用各種方式使代碼運行得更快,例如刪除死代碼(DCE) 、常量折疊、傳播優化等等策略。 後端(又叫代碼生成器)將代碼與任務指令一一對應起來。除了生成正確的代碼以外,也要與機器設備的特性結合以保證生成代碼的質量。通常編譯器後端包括指令選擇、寄存器分配和指令安排表等功能。JVM 也是採用這種模式,使用 Java 字節碼作為前端與優化器的接口來實現的。
編譯器的分段式架構使得开發分工更加明確。比如擅長編譯器前端設計的开發人員,可以注重於編譯器前端的設計,而不用考慮應該為後端優化器和編譯器後端預留相應的資源以及進行什么樣的配置。這也使得相關社區人員可以快速融入進來,實現自己力所能及的那部分。
三段式的結構設計是非常好的,但是因為各個編程語言的編譯器和優化器的實現沒有採用統一的 AST 和 IR 數據結構,導致對編譯器鏈路的各個組成部分進行重用仍異常困難。
LLVM 編譯器架構
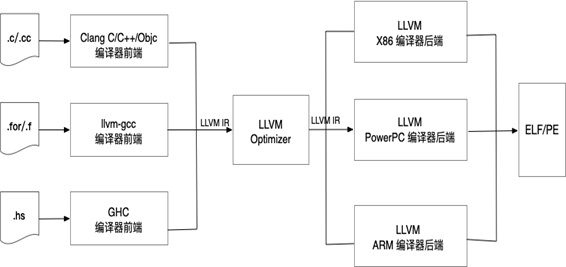
根據上述架構圖我們可以看到 LLVM 編譯器採用的是跟傳統編譯器相同的三段式架構,但存在明顯的區別,即 LLVM 編譯器架構的優化器輸入和輸出都是 LLVM-IR。 LLVM-IR 是 LLVM 框架構建的核心基礎,它確立了IR的規範,使得其不同於傳統的編譯器前後端,將整體架構徹底拆分為三段式,方便开發人員進行分工。
總結:我們經常使用的 Clang 只是一個 LLVM 編譯器前端,它是狹義的 LLVM。 而 GCC 是一個完整的可執行文件,沒有給其它語言的开發者提供代碼重用的接口,因此復用靜態庫做靜態分析或者代碼重構時就會變得特別困難。而且腳本語言經常是通過動態解釋嵌入到即將運行的大型應用程序中,這使得代碼變得非常臃腫,復用其中的某一模塊幾乎不可能。 而 LLVM 作為後起之秀,既傳承了三段式編譯設計,又給开發者提供了可重用的編譯前端和後端的接口,讓开發者幾乎不費力氣就可以完成一個新語言的編譯器前端。
LLVM 編譯過程
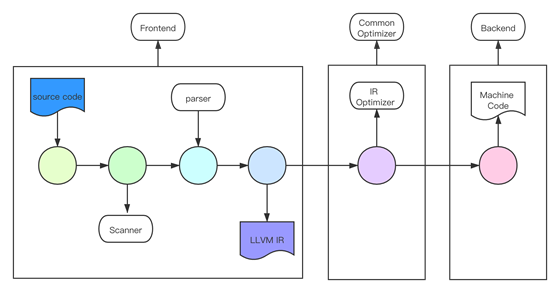
LLVM 編譯過程涉及到前端、優化器、後端三部分的交互。具體過程如下:
Clang 讀取源文件,並將源文件進行預處理。預處理的過程主要為:宏展开、導入頭文件等。
詞法分析器通過 Sanner 掃描處理過的源文件,生成 Token 序列,這個過程一般採用 Lex 完成。
語法分析在 Clang 中由 Parser 和 Sema 兩個模塊配合完成。根據定義好的語法(Grammar),對 Token 序列構成的輸入文本進行分析並確定其語法結構。語法分析的過程會使用自頂向下或者自底向上的方式進行推導,最終形成AST(抽象語法樹)。
CodeGen 負責將語法樹從頂至下遍歷,翻譯成 LLVM IR。LLVM IR 既是 Frontend 的輸出,也是 LLVM Backend 的輸入。
通用優化器負責優化 LLVM IR, 可能會進行死代碼刪除(DCE) 、常量折疊、傳播優化等過程。
最後 LLVM 後端根據 LLVM IR 生成特定平臺可執行代碼。
LLVM 常用工具鏈
為了方便介紹以下的工具鏈,我們編寫一個簡單的hello.c文件
#include<stdio.h>int main() {
printf('Hello World!');
return 0;
}
Clang 編譯器
Clang 本身不屬於 LLVM 命令行工具的一部分,但是因為它是基於 LLVM 工具鏈开發的,使得它擁有了其他類似編譯器不具備的功能,使用 Clang 可以將高級語言的源文件編譯為LLVM-IR中間代碼
Clang -S -emit-llvm hello.c
在上面的命令中 參數 “-S” 指定編譯器生成包含具有可讀性匯編代碼的目標文件; 參數 “-emit-llvm” 用於設置編譯器以LLVM-IR的形式生成目標文件,該參數需要配合 “-S” 參數一起使用。當該命令執行完成後,會在當前目錄生成一個名為 “hello.ll” 的文件, 文件名後綴為 “.ll”, 表示這是一個含有可讀 LLVM-IR 代碼的 ASCII 文本文件。
LLVM-IR 解釋器 - lli
通過 lli 命令,我們可以直接調用專門為 LLVM-IR 設計的即時解釋器,解釋器會逐行解釋並執行目標文件內的 IR 代碼。

LLVM-IR 優化器 - opt
通過 opt 命令,我們可以直接在命令行中調用 LLVM 工具鏈提供的 IR 代碼優化器對 LLVM-IR 代碼優化,該優化器同時支持對可讀文本以及二進制格式下的 LLVM-IR 代碼進行優化,並且可以通過參數執行相應的優化策略。
優化策略比較多,這裏不一一列舉,只列舉一些常用的策略
-mem2reg:該策略會將IR內的內存級變量引用提升為寄存器級變量引用
“-constprop” :該策略主要是用於 “常量傳播優化”
“-dce” :該策略主要是用於刪除死代碼(無法執行到的代碼)
opt -S -mem2reg -constprop -dce hello.ll
LLVM 靜態編譯器 - llc
llc 是 LLVM 命令行工具提供的一個靜態編譯器。通過該編譯器,可以將一個包含有 LLVM-IR 代碼的 “.ll' 文件編譯為以 “.s” 結尾的為特定平臺架構的匯編代碼文件。
llc hello.ll
執行完上述命令,會在當前目錄生成一個 hello.s 的匯編文件,因為我的機器是 mac os 的,所以生成的匯編文件中會帶有 mac os version 等字樣
LLVM 匯編器 - llvm-as
通過 llvm-as 命令行工具,可以將包含有可讀文本格式的 LLVM-IR 文件轉為二進制格式的 LLVM 比特碼
llvm-as hello.ll
執行完上述命令,會在當前目錄生成一個 hello.bc 的比特碼文件,可以通過 hexdump 查看文件具體內容
LLVM 符號表查看器 - llvm-nm
通過 llvm-nm 命令行工具,我們可以查看一個包含二進制 LLVM-IR 比特碼的 “.bc” 文件內的符號表信息

上述命令中, “-A” 參數表示在輸出結果中顯示每個符號的來源文件名。 查看該輸出可知在這個 LLVM 模塊中存在兩個符號,一個是內部名為 “main” 的符號,該符號對應着源碼中的主函數,“T” 表示該函數是一個全局對象函數。“printf” 符號是引用外部標准庫的函數, 所以用 “U”表示。
上面的實例中,我們生成了多個包含不同狀態的 LLVM-IR 中間代碼,以及面向特定底層平臺架構的匯編代碼,對於這些文件,我們都可以使用 Clang 將其編譯為可執行的二進制文件。

總結
本文簡單介紹了 LLVM 項目,讓讀者能夠了解 LLVM 項目的整體架構,懂得通過改造 LLVM 編譯器前端,可以適配多種高級編程語言,包括 Java、Rust、Solidity 等。 鑑於直接通過 Solidity 生成 LLVM IR 難度較大,且 Solidity 語法變更迅速,开發者可通過 Solidity 生成中間語言 YUL ,將 YUL 作為輸入提供給 LLVM 前端生成 LLVM IR 字節碼,即各種零知識證明需要的表示形式,最後在 ZKEVM 中執行。從理論上來講這套邏輯沒有任何問題,但是實際執行的工程難度還是非常大的,具體細節需要研究後再做定論。
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
Uniswap公告Unichain主網明年初上線!首測路線圖兩功能,UNI強彈17%
去 中心化交易所(DEX)龍頭 Uniswap 於 10 月宣佈推出專為 DeFi 設計的 Lay...
下周必關注|LayerZero決定是否开啓“費用开關”;Aligned空投注冊結束(12.23-12.29)
下周重點預告 12 月 23 日 Aligned 將向 891322 個地址空投 26% 的 AL...
空投周報 | OpenSea基金會官推上线;Azuki、Doodles疑似即將發幣(12.16-12.22)
@OdailyChina @web3_golem Odaily星球日報盤點了 12 月 16 日至...
資金費率的演變:從2021年黃金時代,到2024-2025年套利復興
資金費率起源 資金費率起源於加密貨幣衍生品市場,特別是從永續期貨合約中發展而來。它作為一種機制,用...
PANews
文章數量
303粉絲數
0